
LEI Data
GLEIF Data Quality Management
Data quality requires proactive actions
Proactive Management
In order to support LEI issuing organizations, GLEIF provides appropriate and mandatory processes together with a technical interface to enable LEI issuers to proactively assess the data quality of an LEI and related reference data. This includes a dedicated check for duplicate entries. LEI records are to be checked one at a time using the automated web service APIs: Data Governance Pre-Check and Check for Duplicates.
Data Governance Pre-Check

The LEI issuers are obliged to send all newly issued and updated LEI records to GLEIF’s Pre-Check facility before uploading these to the global repository. The Pre-Check facility applies the same Data Quality Checks that are also carried out on a daily basis for already published LEI Records. Based on the Pre-Check results, LEI Issuers can remediate potential data quality issues before these inconsistencies enter the public data pool. In addition to the check result, the requester also receives an explanation, which facilitates a focused and speedy remediation of the reported issue.
The mandatory usage of the facility by LEI issuing organizations supports the continual improvement process, raising the bar on quality and increasing the maturity level of the data in the Global LEI System.
Check for Duplicates
To prevent duplicated data records, newly requested LEI codes and corresponding reference data are compared to all other records in the Global LEI Repository as well as to LEI records that have been submitted to the Check for Duplicates facility by other LEI issuers, but have not yet been issued. Therefore, even if two separate LEI Issuers have been approached by the same legal entity, the LEI Issuers will identify potential duplicates and are able to coordinate with their clients and with one another. Ultimately, this procedure prevents the introduction of duplicates in the system.
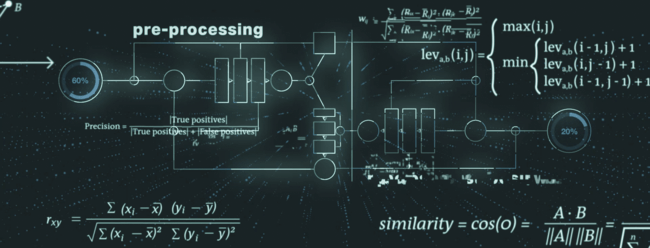
The process of identifying duplicates considers multiple data elements of the LEI record and can be divided into pre-processing, core algorithm and post-processing.
During pre-processing, the data is prepared for the upcoming steps, like for instance the so-called weak tokens are identified and taken care of. A typical example for a weak token is the legal form of the legal entity which can be part of the legal entity’s name. The legal forms could be then normalized and harmonized to ensure best possible results in the following process stages.
The core engine of the Check for Duplicates facility consists of a uniqueness and an exclusivity check, combining state-of-the-art algorithms for fuzzy string matching (e.g., Levenshtein distance, Cosine similarity, Monge-Elkan distance).
In the post-processing step, the Check for Duplicates facility reduces the number of false positives based on additional checks and special treatment of secondary data elements (e.g., legal jurisdiction, entity category).
Relevant Files for Download
Download as PDF: Check for Duplicates Dictionary v1.2