Le traduzioni di questo sito web in lingue diverse dall'inglese sono generate dall'IA. Non garantiamo l'accuratezza e non siamo responsabili per eventuali errori o danni derivanti dall'uso del contenuto tradotto. In caso di incongruenze o ambiguità, la versione inglese prevarrà.
Newsroom e media
Blog della GLEIF
Le traduzioni di questo sito web in lingue diverse dall'inglese sono generate dall'IA. Non garantiamo l'accuratezza e non siamo responsabili per eventuali errori o danni derivanti dall'uso del contenuto tradotto. In caso di incongruenze o ambiguità, la versione inglese prevarrà.
Trasformare i dati in opportunità: Metric in Motion – Come l’IA può rafforzare la trasparenza sulla proprietà
Le organizzazioni si affidano sempre più ai dati sulle relazioni per la gestione dei rischi, la due diligence, la conformità e la trasparenza. In questo blog, Zornitsa Manolova, responsabile della gestione della qualità dei dati e della scienza dei dati presso GLEIF, esplora come l'IA offra nuove opportunità per migliorare la qualità, la completezza e l'accessibilità di informazioni affidabili sulla proprietà su larga scala.
Autore: Zornitsa Manolova
Data: 2026-06-08
Visualizzazioni:
In un'economia globale sempre più interconnessa, la capacità delle organizzazioni di fidarsi dei dati e di utilizzarli in modo efficace è alla base dell'innovazione, della crescita e della competitività.
Un ecosistema di dati di alta qualità è un motore di cambiamento e innovazione che consente alle organizzazioni di identificare e cogliere nuove opportunità, mentre una bassa qualità dei dati può portare a inefficienze ed esposizione a rischi normativi e reputazionali.
Per favorire una più ampia consapevolezza del settore riguardo alle iniziative di qualità dei dati della GLEIF e alla loro applicazione in diversi settori, questa nuova serie di blog esplora le metriche chiave incluse nei rapporti.
Il tema centrale di questo mese: come l’IA può rafforzare la trasparenza della proprietà.
Man mano che le strutture aziendali globali diventano più complesse, l’accesso a dati affidabili sulla proprietà e sulle relazioni diventa sempre più importante per la trasparenza, la responsabilità e la comprensione dei rischi. Questi dati, che includono le relazioni tra società madri e controllate, aiutano le organizzazioni a valutare i rischi, a garantire la Conformità e a prendere decisioni più informate, mostrando come le persone giuridiche sono collegate tra loro.
All’interno del Sistema globale di identificazione delle persone giuridiche, i dati di secondo livello forniscono questo contesto fondamentale identificando le strutture societarie di società madri e controllate, i collegamenti tra filiali e sedi centrali e le relazioni tra fondi. Spesso descritti come la risposta alla domanda “chi detiene chi”, i dati di secondo livello aiutano a rivelare le strutture che stanno dietro alle persone giuridiche e rafforzano la fiducia negli ecosistemi finanziari e aziendali.
Comprendere il valore dei dati di Livello 2 nel Sistema LEI Globale
Un recente sondaggio condotto dal Comitato di supervisione regolamentare (ROC) e dalla GLEIF evidenzia il valore dei dati di Livello 2. Circa il 70% degli intervistati ha dichiarato di utilizzare i dati di Livello 2, mentre quasi l’85% li considera dati di qualità. Gli intervistati hanno inoltre confermato che i dati di Livello 2 sono già integrati nel processo decisionale delle loro organizzazioni e hanno riferito di utilizzare tali dati a supporto di vari processi operativi e strategici, con molti che apprezzano in particolare le relazioni consolidate con le società madri.
Questi risultati evidenziano una tendenza chiave. Con l'aumentare della domanda di informazioni affidabili sulla proprietà, è fondamentale mantenere dati di relazione di alta qualità su larga scala.
L'intelligenza artificiale apre nuove possibilità per l'estrazione dei dati sulle relazioni
Con l'intelligenza artificiale (AI) che sta trasformando il modo in cui le organizzazioni gestiscono e analizzano i dati, stanno emergendo nuove opportunità per soddisfare questa esigenza di migliorare ulteriormente la qualità, la completezza e l'affidabilità dei dati sulle relazioni.
Ad esempio, informazioni preziose sulle relazioni sono già ampiamente disponibili, ma spesso è difficile accedervi perché sono sepolte nei bilanci annuali e in altre comunicazioni societarie. I dettagli relativi alle società madri e alle controllate possono apparire in note a piè di pagina, tabelle, note al bilancio o sezioni descrittive. Queste informazioni sono spesso frammentate, formattate in modo incoerente e difficili da esaminare manualmente su larga scala, rendendo difficile integrarle in set di dati strutturati.
L’estrazione basata sull’intelligenza artificiale offre un modo pratico per sbloccare queste informazioni nascoste. Identificando, interpretando e strutturando i dettagli sulla proprietà da relazioni annuali e altri complessi documenti PDF, l’intelligenza artificiale può aiutare a trasformare informazioni non strutturate in dati strutturati sulle relazioni. Può inoltre confrontare le informazioni tra i vari documenti. Ciò può migliorare il recupero e la convalida dei dati di Livello 2, supportando una migliore analisi dei rischi e un processo decisionale più efficace e migliorando la qualità complessiva e la trasparenza del Sistema LEI Globale.
Infatti, la GLEIF sta già utilizzando l’estrazione basata sull’IA per recuperare i dati sulle relazioni dai bilanci annuali e convertirli in un formato strutturato. Ciò consente alla GLEIF di esaminare e confermare le informazioni esistenti sulle relazioni nell’Indice globale dei codici LEI, o di attivare aggiornamenti dove necessario, al di fuori del processo di rinnovo annuale. Di conseguenza, i dati sulle relazioni possono essere mantenuti più aggiornati e affidabili nel tempo.
I progressi compiuti da Transparency Fabric – un'iniziativa congiunta introdotta da GLEIF, Open Ownership e OpenSanctions – nel 2025 ha introdotto anche l’uso di modelli linguistici di grandi dimensioni (LLM) per estrarre e analizzare informazioni da documenti non strutturati, al fine di mappare meglio le complesse strutture proprietarie e supportare il collegamento dei LEI con i dati sulla titolarità effettiva e sulle sanzioni.
Come funziona
Il processo automatizzato identifica tutte le controllate delle società madri in un PDF di relazione annuale utilizzando un processo LLM in più fasi:
In primo luogo, l’IA esamina la relazione e identifica le possibili controllate sulla base delle definizioni e degli esempi forniti. Successivamente, verifica i propri risultati per individuare potenziali lacune, controllate mancanti o voci che potrebbero essere state incluse in modo errato.
Dopo questa revisione, i risultati vengono perfezionati in un elenco finale nel formato richiesto. Ciò include la rimozione dei falsi positivi, l'aggiunta di eventuali controllate mancanti, la verifica dei riferimenti alle pagine pertinenti e la standardizzazione di dettagli quali le informazioni sulla giurisdizione o sul paese.
Infine, l'elenco generato dall'IA può essere confrontato con un elenco estratto manualmente per valutarne l'accuratezza, la completezza e la qualità complessiva.
Ciò dimostra come l'IA possa aiutare ad accelerare l'estrazione dei dati delle controllate da documenti PDF complessi. Allo stesso tempo, la supervisione umana rimane importante per convalidare i risultati, migliorare la qualità e garantire l'affidabilità dei dati finali sulle relazioni.
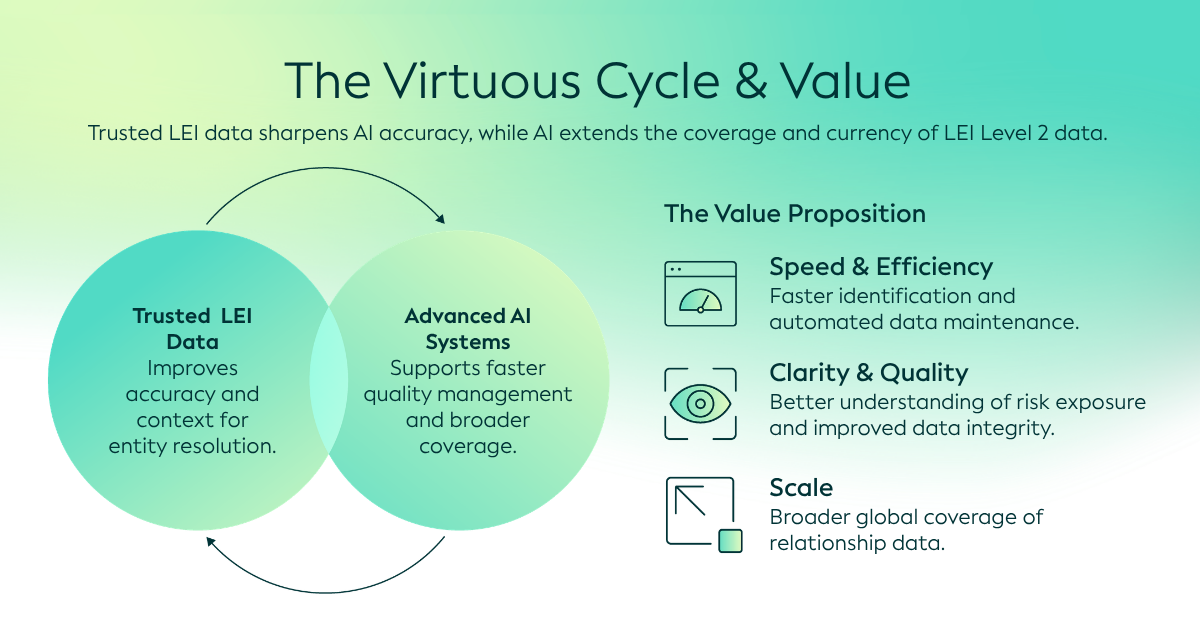
Utilizzo di dati LEI affidabili per migliorare l’IA stessa
Mentre l'IA può aiutare a trovare e verificare i dati sulle relazioni di Livello 2, i dati LEI affidabili possono, a loro volta, migliorare l'uso dei metodi di IA per questo compito.
La GLEIF ha utilizzato i dati LEI esistenti e le relazioni annuali per ottimizzare i prompt utilizzando l’approccio GEPA, ovvero la Genetic Pareto Reflective Prompt Evolution. Anziché indovinare quale prompt possa funzionare meglio, il GEPA utilizza dati etichettati e feedback umani per sviluppare varianti di prompt più efficaci, testarle rispetto a esempi noti e mantenere i compromessi più performanti.
Questo approccio sposta lo sviluppo dell’IA dalla sperimentazione al miglioramento misurabile. Ad esempio, un prompt ottimizzato con GEPA ha migliorato l’accuratezza misurabile delle informazioni sulle relazioni recuperate. Ancora più interessante è il fatto che, dopo l’ottimizzazione, un modello più piccolo ed economico abbia funzionato meglio di uno più grande e costoso. Ciò dimostra che dati di alta qualità e un’ottimizzazione strutturata spesso contano più dell’utilizzo di un modello più grande. In parole povere, input migliori creano output migliori.
Combinare l'innovazione dell'IA con basi di dati affidabili
Il risultato più prezioso dell’estrazione di dati relazionali guidata dall’IA è la capacità di trasformare informazioni frammentarie in intelligence relazionale affidabile, strutturata e utilizzabile, consentendo alle organizzazioni di prendere decisioni più informate nell’economia globale.
Tuttavia, framework affidabili, Governance e identificatori standardizzati rimangono essenziali per garantire che queste informazioni siano affidabili e utilizzabili. Combinando l’innovazione dell’IA con le basi affidabili del Sistema LEI Globale, si ha l’opportunità di rafforzare la qualità, la copertura e l’usabilità dei dati sulla proprietà e sulle relazioni su larga scala.
Per commentare un articolo del blog, indicate il vostro nome e cognome. Il nome e il cognome verranno visualizzati accanto al commento. Gli indirizzi e-mail non verranno pubblicati. Effettuando l’accesso o contribuendo al forum di discussione, l’utente accetta i termini della Politica in materia di blog della GLEIF. Si invita pertanto l’utente a leggere tale politica con attenzione.
Zornitsa Manolova guida il team Gestione della qualità dei dati e Scienza dei dati presso la Global Legal Entity Identifier Foundation (GLEIF). Dall'aprile 2018 ha la responsabilità di promuovere e migliorare l'esistente quadro di qualità e governance dei dati introducendo approcci analitici innovativi. In precedenza, ha gestito progetti di analisi dei dati forensi in indagini finanziarie internazionali presso PwC Forensics. Zornitsa ha conseguito la laurea in scienze informatiche con specializzazione in Apprendimento automatico presso l'Università di Marburgo (Philipps-Universität Marburg).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
