As traduções deste site em idiomas diferentes do inglês são geradas por IA. Não garantimos a precisão e não nos responsabilizamos por quaisquer erros ou danos resultantes do uso do conteúdo traduzido. Em caso de inconsistências ou ambiguidades, versão em inglês prevalecerá.
Sala de Imprensa e Mídia
Blog da GLEIF
As traduções deste site em idiomas diferentes do inglês são geradas por IA. Não garantimos a precisão e não nos responsabilizamos por quaisquer erros ou danos resultantes do uso do conteúdo traduzido. Em caso de inconsistências ou ambiguidades, versão em inglês prevalecerá.
Transformar dados em oportunidades: Metric in Motion – Como a IA pode reforçar a transparência na titularidade
As organizações dependem cada vez mais dos dados de relações para a Gestão de Riscos, due diligence, Conformidade e transparência. Neste blogue, Zornitsa Manolova, Diretora de Gestão da Qualidade de Dados e Ciência de Dados na GLEIF, explora como a IA oferece novas oportunidades para melhorar a qualidade, a integridade e a acessibilidade de informações fiáveis sobre a propriedade em grande escala.
Autor: Zornitsa Manolova
Data: 2026-06-08
Visualizações:
Numa economia global cada vez mais interligada, a capacidade das organizações de confiar e utilizar dados de forma eficaz é a base da inovação, do crescimento e da competitividade.
Um ecossistema de dados de alta qualidade é um motor de mudança e inovação que permite às organizações identificar e aproveitar novas oportunidades, enquanto a baixa qualidade de dados pode levar a ineficiências e à exposição a riscos regulamentares e de reputação.
Para ajudar a sensibilizar o setor para as iniciativas de Qualidade de Dados da GLEIF e a sua aplicação em diferentes setores, esta nova série de artigos explora as principais métricas incluídas nos relatórios.
O foco deste mês: como a IA pode reforçar a transparência da propriedade.
À medida que as estruturas corporativas globais se tornam mais complexas, o acesso a dados fiáveis sobre propriedade e relações é cada vez mais importante para a transparência, a responsabilização e a compreensão dos riscos. Estes dados, que incluem relações entre empresas-mãe e subsidiárias, ajudam as organizações a avaliar riscos, a apoiar a Conformidade e a tomar decisões mais informadas, mostrando como as Entidades Jurídicas estão interligadas.
No âmbito do Global Legal Entity Identifier System, os dados de Nível 2 fornecem este contexto crítico, identificando estruturas corporativas de empresas-mãe e subsidiárias, ligações entre sucursais e sedes e relações entre fundos. Frequentemente descritos como respondendo à pergunta «quem controla quem», os dados de Nível 2 ajudam a revelar as estruturas por trás das Entidades Jurídicas e reforçam a confiança nos ecossistemas financeiros e empresariais.
Compreender o valor dos dados de Nível 2 no Sistema Global LEI
Um inquérito recente realizado pelo Comitê de Supervisão Regulatória (ROC) e pela GLEIF destaca o valor dos dados de Nível 2. Aproximadamente 70% dos inquiridos referiram utilizar dados de Nível 2, enquanto quase 85% afirmaram considerá-los dados de qualidade. Os inquiridos confirmaram também que os dados de Nível 2 já estão integrados no processo de tomada de decisões das suas organizações e referiram utilizar dados de Nível 2 para apoiar vários processos operacionais e estratégicos, sendo que muitos valorizam, em particular, as relações consolidadas com a empresa-mãe.
Estas conclusões destacam uma tendência fundamental. À medida que a procura por informações fiáveis sobre a propriedade aumenta, é fundamental manter dados de relações de alta qualidade em grande escala.
A IA abre novas possibilidades para a extração de dados de relações
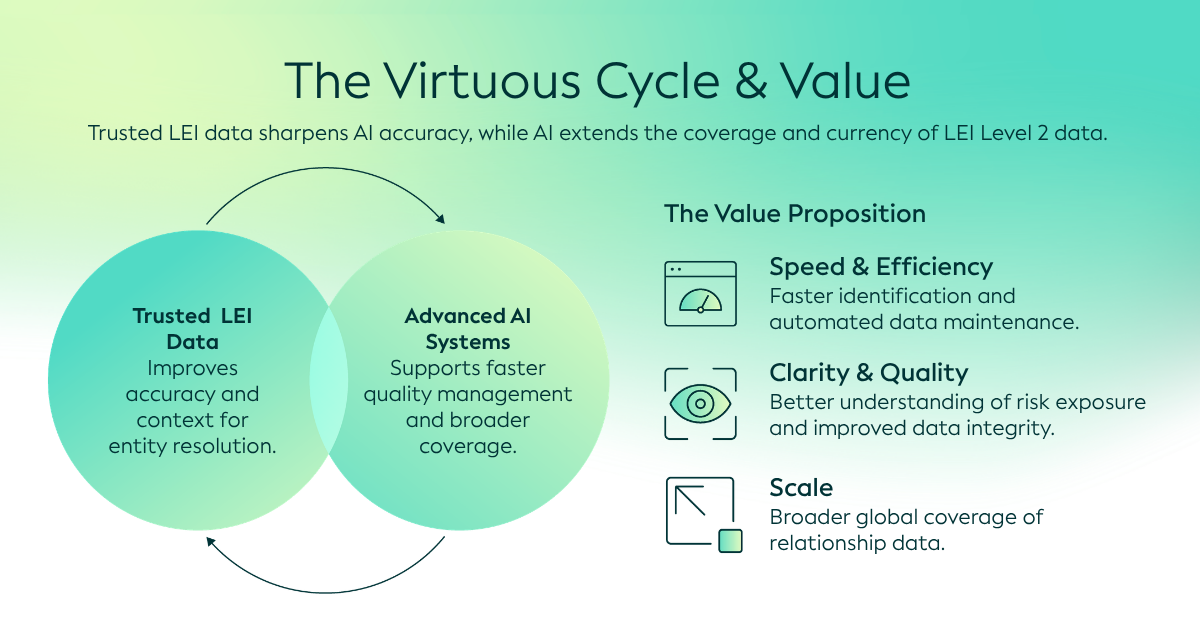
Com a inteligência artificial (IA) a transformar a forma como as organizações gerem e analisam dados, estão a surgir novas oportunidades para responder a esta necessidade de melhorar ainda mais a qualidade, a exaustividade e a fiabilidade dos dados de relações.
Por exemplo, informações valiosas sobre relações já estão amplamente disponíveis – mas muitas vezes são difíceis de aceder porque estão enterradas em relatórios anuais e outras divulgações corporativas. Os detalhes sobre a empresa-mãe e as subsidiárias podem aparecer em notas de rodapé, tabelas, notas às demonstrações financeiras ou secções narrativas. Estas divulgações são frequentemente fragmentadas, apresentam formatação inconsistente e são difíceis de analisar manualmente em grande escala, tornando-se um desafio integrá-las em conjuntos de dados estruturados.
A extração impulsionada pela IA oferece uma forma prática de desbloquear esta informação oculta. Ao identificar, interpretar e estruturar detalhes de propriedade a partir de relatórios anuais e outros documentos PDF complexos, a IA pode ajudar a transformar informação não estruturada em dados de relações estruturados. Também pode comparar informação entre documentos. Isto pode melhorar a recuperação e validação de dados de Nível 2, apoiando uma melhor análise de risco e tomada de decisões e melhorando a qualidade e transparência globais do Sistema Global LEI.
De facto, a GLEIF já está a utilizar a extração baseada em IA para recuperar os dados de relações a partir de relatórios anuais e convertê-los num formato estruturado. Isto permite à GLEIF rever e confirmar as informações de relações existentes no Global LEI Index, ou desencadear atualizações quando necessário, fora do processo de renovação anual. Como resultado, os dados de relações podem ser mantidos mais atualizados e fiáveis ao longo do tempo.
Avanços na Transparency Fabric – uma iniciativa conjunta lançada pela GLEIF, Open Ownership e OpenSanctions – em 2025 introduziram também a utilização de Modelos de Linguagem de Grande Dimensão (LLMs) para extrair e analisar informações de documentos não estruturados, a fim de mapear melhor estruturas de propriedade complexas e apoiar a ligação dos LEIs com dados sobre a propriedade efetiva e sanções.
Como funciona
O processo automatizado identifica todas as subsidiárias de empresas-mãe num relatório anual em PDF utilizando um processo LLM em várias etapas:
Primeiro, a IA analisa o relatório e identifica possíveis subsidiárias com base nas definições e exemplos fornecidos. Em seguida, verifica os seus próprios resultados para identificar potenciais lacunas, subsidiárias em falta ou entradas que possam ter sido incluídas incorretamente.
Após esta análise, os resultados são refinados numa lista final no formato exigido. Isto inclui a remoção de falsos positivos, a adição de quaisquer subsidiárias em falta, a verificação das referências de página relevantes e a padronização de detalhes, tais como informações sobre jurisdição ou país.
Por fim, a lista gerada pela IA pode ser comparada com uma lista extraída manualmente para avaliar a precisão, a exaustividade e a qualidade geral.
Isto demonstra como a IA pode ajudar a acelerar a extração de dados de subsidiárias a partir de documentos PDF complexos. Ao mesmo tempo, a combinação com a supervisão humana continua a ser importante para validar os resultados, melhorar a qualidade e garantir que os dados finais sobre relações são fiáveis.
Utilizar dados LEI fiáveis para melhorar a própria IA
Embora a IA possa ajudar a encontrar e verificar dados de relações de Nível 2, dados LEI fiáveis podem, por sua vez, melhorar a utilização de métodos de IA para esta tarefa.
A GLEIF utilizou dados LEI existentes e relatórios anuais para otimizar prompts utilizando a abordagem GEPA, ou Genetic Pareto Reflective Prompt Evolution. Em vez de adivinhar qual o prompt que poderá ter melhor desempenho, a GEPA utiliza dados rotulados e feedback humano para desenvolver variantes de prompts mais robustas, testá-las em relação a exemplos conhecidos e reter as soluções de compromisso com melhor desempenho.
Esta abordagem faz com que o desenvolvimento da IA passe da experimentação para uma melhoria mensurável. Por exemplo, um prompt otimizado pela GEPA melhorou a precisão mensurável das informações de relacionamento recuperadas. Ainda mais interessante é o facto de um modelo mais pequeno e mais barato ter tido um desempenho melhor do que um modelo maior e mais caro após a otimização. Isto demonstra que dados de alta qualidade e otimização estruturada são frequentemente mais importantes do que a utilização de um modelo maior. Em termos simples, melhores entradas geram melhores resultados.
Combinar a inovação em IA com bases de dados fiáveis
O resultado mais valioso da extração de dados de relações impulsionada pela IA é a capacidade de transformar divulgações fragmentadas em inteligência de relações fiável, estruturada e acionável – permitindo que as organizações tomem decisões mais informadas em toda a economia global.
No entanto, estruturas fiáveis, Governança e identificadores padronizados continuam a ser essenciais para garantir que estas informações sejam fiáveis e utilizáveis. Ao combinar a inovação em IA com as bases fiáveis do Sistema Global de LEI, existe uma oportunidade de reforçar a qualidade, a cobertura e a usabilidade dos dados de propriedade e de relações em grande escala.
Caso queira comentar uma postagem no blog, identifique-se usando seu nome e sobrenome. Seu nome aparecerá ao lado de seu comentário. Endereços de e-mail não serão publicados. Note que ao acessar ou contribuir com o fórum de discussão, você concorda com os termos da Política de Uso do Blog da GLEIF, portanto, leia-a com atenção.
Zornitsa Manolova lidera a equipe de Gestão de Qualidade de Dados e Ciência de Dados na Global Legal Entity Identifier Foundation (GLEIF). Desde abril de 2018, ela é responsável por aprimorar e melhorar a qualidade de dados estabelecida e a estrutura de governança de dados, introduzindo abordagens inovadoras de análise de dados. Anteriormente, Zornitsa gerenciou projetos de análise de dados forenses em investigações financeiras internacionais na PwC Forensics. Ela é formada em ciências da computação com foco em aprendizagem de máquina pela Universidade Philipps de Marburgo.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
