
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
阅读先前全部 GLEIF 博文 >
关于作者:

Zornitsa Manolova 是 Global Legal Entity Identifier Foundation (GLEIF) 数据质量管理和数据科学团队的领导者。自 2018 年 4 月起,她负责通过引入创新的数据分析方法来加强和改进既定的数据质量和数据治理框架。在此之前,Zornitsa 曾在普华永道法证部门负责管理国际金融调查的法证数据分析项目。她拥有德国马尔堡菲利普大学的计算机科学专业学位,主修机器学习。

在日益互联的全球经济中,组织能否有效信任并利用数据,是创新、增长和竞争力的基石。
高质量的数据生态系统是推动变革与创新的引擎,使组织能够识别并把握新机遇;而低质量的数据则可能导致效率低下,并使组织面临监管和声誉风险。
为帮助业界更广泛地了解 GLEIF 的数据质量倡议及其在不同领域的应用,本新博客系列将探讨报告中包含的关键指标。
本月焦点:人工智能如何增强所有权透明度。
随着全球企业结构日益复杂,获取可信的所有权和关联数据对于透明度、问责制和风险洞察变得愈发重要。这些数据(包括母公司与子公司之间的关系)通过展示法定实体之间的关联,帮助组织评估风险、支持合规并做出更明智的决策。
在全球LEI系统中,二级数据通过识别母公司与子公司结构、分支机构与总部之间的联系以及基金关系,提供了这一关键背景信息。二级数据常被描述为回答“谁拥有谁”这一问题,它有助于揭示法定实体背后的结构,并增强金融和商业生态系统中的信任。

理解全球LEI系统中二级数据的价值
监管委员会(ROC)与全球LEI基金会(GLEIF)近期开展的一项调查突显了二级数据的价值。约70%的受访者表示正在使用二级数据,而近85%的受访者认为该数据质量上乘。 受访者还证实,二级数据已融入其组织的决策流程,并表示利用二级数据支持各类运营和战略流程,其中许多人特别重视整合后的母公司关系信息。
这些发现凸显了一个关键趋势。随着对可靠所有权信息需求的增加,大规模维护高质量的关系数据至关重要。

人工智能为关联数据提取开辟新可能
随着人工智能(AI)正在改变组织管理和分析数据的方式,新的机遇正在涌现,以满足进一步提升关系数据质量、完整性和可靠性的需求。
例如,有价值的关联信息其实已广泛存在——但往往难以获取,因为它们深埋在年报和其他公司披露文件中。 母公司与子公司的详细信息可能出现在脚注、表格、财务报表附注或叙述性章节中。这些披露内容往往零散、格式不统一,且难以进行大规模人工审查,因此将其整合到结构化数据集中颇具挑战。
基于人工智能的提取技术为挖掘这些隐藏信息提供了一种切实可行的方法。通过识别、解读并整理年度报告及其他复杂 PDF 文档中的所有权细节,人工智能能够将非结构化信息转化为结构化的关联数据,并可实现跨文档的信息比对。 这有助于提升二级数据的检索和验证效率,从而支持更精准的风险分析和决策制定,并提升全球LEI系统的整体质量与透明度。
事实上,GLEIF 已开始利用基于 AI 的数据提取技术,从年度报告中提取关联数据并将其转换为结构化格式。这使 GLEIF 能够在年度更新流程之外,审查并确认全球 LEI 索引中的现有关联信息,或在必要时触发更新。因此,关联数据能够随着时间的推移保持更高的时效性和可信度。
“透明度架构”的进展——这是由 GLEIF、 Open Ownership 及 OpenSanctions 于 2025 年共同推出的联合倡议——还引入了大型语言模型(LLMs)的应用,用于从非结构化文档中提取和分析信息,从而更好地映射复杂的股权结构,并支持将 LEI 与实际受益人所有权及制裁数据进行关联。
工作原理
该自动化流程通过LLM多步骤流程,识别年度报告PDF文件中母公司的所有子公司:
这展示了AI如何帮助加速从复杂的PDF文档中提取子公司数据。与此同时,结合人工监督对于验证结果、提升质量以及确保最终关联数据的可靠性依然至关重要。
利用可信的LEI数据提升AI本身
虽然人工智能有助于查找和核查二级关联数据,但可信的LEI数据反过来也能增强人工智能方法在此任务中的应用效果。
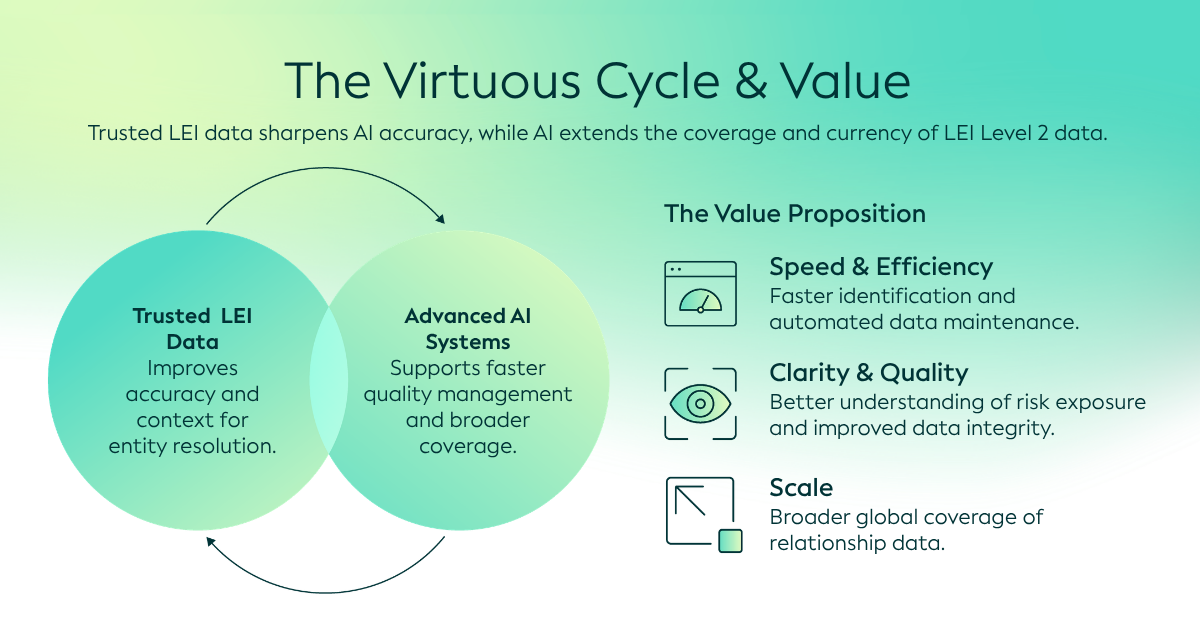
GLEIF利用现有LEI数据和年度报告,通过GEPA(遗传帕累托反射提示演化)方法优化提示词。GEPA并非凭空猜测哪种提示词表现最佳,而是利用标注数据和人工反馈来演化更强大的提示词变体,用已知示例对其进行测试,并保留表现最佳的折中方案。
这种方法将人工智能开发从实验阶段转向了可量化的改进。 例如,经 GEPA 增强的提示词显著提升了检索到的关联信息的可量化准确率。更有趣的是,优化后,一个更小、更经济的模型表现竟优于更大、更昂贵的模型。这表明,高质量数据和结构化优化往往比使用更大规模的模型更为关键。简而言之,更好的输入才能产生更好的输出。
将人工智能创新与可信数据基础相结合
人工智能驱动的关系数据提取所带来的最具价值的成果,在于能够将零散的披露信息转化为可靠、结构化且可操作的关系情报——从而使组织能够在全球经济中做出更明智的决策。
然而,可信的框架、治理机制和标准化标识符仍是确保这些洞察可靠且可用的关键。通过将人工智能创新与全球法律实体标识符(LEI)系统的可信基础相结合,我们有机会在更大范围内提升所有权和关联数据的质量、覆盖范围及可用性。

如果您希望对博文进行评论,请使用您的姓名来识别自己。您的姓名将显示在您的评论旁。不会公布电子邮件地址。请注意,访问讨论区或在其中发帖即表示您同意遵守GLEIF 博客政策条款,因此请仔细阅读该条款。
Zornitsa Manolova 是 Global Legal Entity Identifier Foundation (GLEIF) 数据质量管理和数据科学团队的领导者。自 2018 年 4 月起,她负责通过引入创新的数据分析方法来加强和改进既定的数据质量和数据治理框架。在此之前,Zornitsa 曾在普华永道法证部门负责管理国际金融调查的法证数据分析项目。她拥有德国马尔堡菲利普大学的计算机科学专业学位,主修机器学习。