الترجمات غير الإنجليزية على هذا الموقع الإلكتروني مدعومة بالذكاء الاصطناعي. نحن لا نضمن الدقة ولسنا مسؤولين عن أي أخطاء أو أضرار ناتجة عن استخدام المحتوى المترجم. في حالة وجود أي تضارب أو غموض، النسخة الإنجليزية تسود.
غرفة الأخبار والإعلام
مدوّنة GLEIF
الترجمات غير الإنجليزية على هذا الموقع الإلكتروني مدعومة بالذكاء الاصطناعي. نحن لا نضمن الدقة ولسنا مسؤولين عن أي أخطاء أو أضرار ناتجة عن استخدام المحتوى المترجم. في حالة وجود أي تضارب أو غموض، النسخة الإنجليزية تسود.
تحويل البيانات إلى فرص: المقاييس المتطورة – كيف يمكن للذكاء الاصطناعي تعزيز شفافية الملكية
تعتمد المؤسسات بشكل متزايد على بيانات العلاقات لإدارة المخاطر، والعناية الواجبة، والالتزام، والشفافية. في هذا المدونة، تستكشف زورنيتسا مانولوفا، رئيسة إدارة جودة البيانات وعلوم البيانات في GLEIF، كيف يوفر الذكاء الاصطناعي فرصًا جديدة لتحسين جودة واكتمال وإمكانية الوصول إلى معلومات الملكية الموثوقة على نطاق واسع.
المؤلف: زورنيتسا مانولوفا
التاريخ: 08-06-2026
مشاهَدات:
في ظل اقتصاد عالمي مترابط بشكل متزايد، تعد قدرة المؤسسات على الوثوق بالبيانات واستخدامها بفعالية أساسًا للابتكار والنمو والقدرة التنافسية.
يعد نظام البيانات عالي الجودة محركًا للتغيير والابتكار يمكّن المؤسسات من تحديد الفرص الجديدة واغتنامها، في حين أن انخفاض جودة البيانات يمكن أن يؤدي إلى عدم الكفاءة والتعرض لمخاطر تنظيمية ومخاطر تتعلق بالسمعة.
للمساعدة في زيادة وعي القطاع بمبادرات GLEIF المتعلقة بجودة البيانات وتطبيقها في مختلف القطاعات، تستكشف سلسلة المدونات الجديدة هذه المقاييس الرئيسية الواردة في التقارير.
موضوع هذا الشهر: كيف يمكن للذكاء الاصطناعي تعزيز شفافية الملكية.
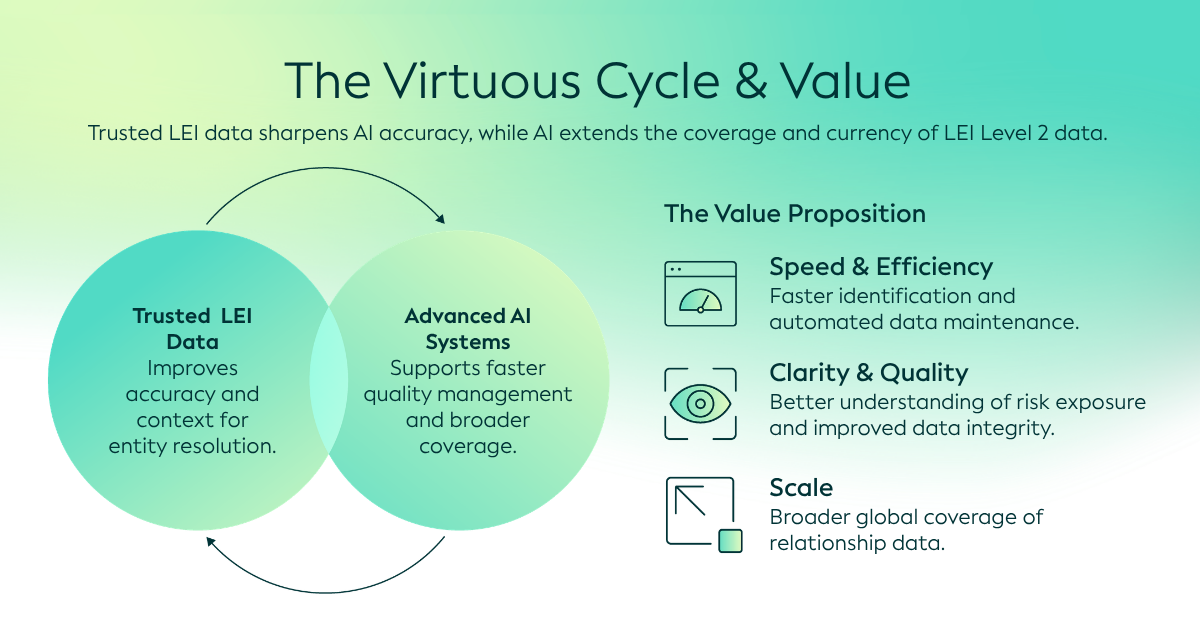
مع تزايد تعقيد الهياكل المؤسسية العالمية، يزداد أهمية الوصول إلى بيانات موثوقة عن الملكية والعلاقات من أجل الشفافية والمساءلة وفهم المخاطر. تساعد هذه البيانات، التي تشمل العلاقات بين الشركات الأم والشركات التابعة، المؤسسات على تقييم المخاطر ودعم الالتزام واتخاذ قرارات أكثر استنارة من خلال إظهار كيفية ارتباط الكيانات القانونية ببعضها البعض.
ضمن نظام معرّفات الكيانات القانونية الدولي، توفر بيانات المستوى الثاني هذا السياق الحاسم من خلال تحديد هياكل الشركات الأم والشركات التابعة، والروابط بين الفروع والمقر الرئيسي، وعلاقات الصناديق. غالبًا ما توصف بيانات المستوى الثاني بأنها تجيب على السؤال "من يملك من"، وتساعد على الكشف عن الهياكل الكامنة وراء الكيانات القانونية وتعزز الثقة عبر النظم البيئية المالية والتجارية.
فهم قيمة بيانات المستوى 2 في نظام LEI العالمي
يسلط استطلاع حديث أجرته لجنة الرقابة التنظيمية العالمية (ROC) و GLEIF الضوء على قيمة بيانات المستوى 2. أفاد حوالي 70% من المشاركين في الاستطلاع باستخدام بيانات المستوى 2، بينما قال ما يقرب من 85% منهم إنهم يعتبرونها بيانات عالية الجودة. كما أكد المشاركون في الاستطلاع أن بيانات المستوى 2 مدمجة بالفعل في عملية صنع القرار في مؤسساتهم، وأفادوا باستخدامها لدعم مختلف العمليات التشغيلية والاستراتيجية، مع تقدير الكثيرين للعلاقات الموحدة مع الشركات الأم على وجه الخصوص.
تسلط هذه النتائج الضوء على اتجاه رئيسي. مع تزايد الطلب على معلومات موثوقة عن الملكية، يصبح الحفاظ على بيانات علاقات عالية الجودة على نطاق واسع أمرًا بالغ الأهمية.
الذكاء الاصطناعي يفتح آفاقًا جديدة لاستخراج بيانات العلاقات
مع قيام الذكاء الاصطناعي (AI) بتحويل الطريقة التي تدير بها المؤسسات البيانات وتحللها، تظهر فرص جديدة لتلبية هذه الحاجة إلى تعزيز جودة واكتمال وموثوقية بيانات العلاقات.
على سبيل المثال، تتوفر معلومات قيمة عن العلاقات على نطاق واسع بالفعل – ولكن غالبًا ما يصعب الوصول إليها لأنها مدفونة في التقارير السنوية والإفصاحات المؤسسية الأخرى. قد تظهر تفاصيل الشركة الأم والشركات التابعة في الحواشي السفلية أو الجداول أو الملاحظات المرفقة بالبيانات المالية أو الأقسام السردية. غالبًا ما تكون هذه الإفصاحات مجزأة وذات تنسيق غير متسق ويصعب مراجعتها يدويًا على نطاق واسع، مما يجعل من الصعب دمجها في مجموعات بيانات منظمة.
يوفر الاستخراج المدعوم بالذكاء الاصطناعي طريقة عملية للوصول إلى هذه المعلومات المخفية. من خلال تحديد تفاصيل الملكية وتفسيرها وتنظيمها من التقارير السنوية ووثائق PDF المعقدة الأخرى، يمكن للذكاء الاصطناعي المساعدة في تحويل المعلومات غير المنظمة إلى بيانات علاقات منظمة. كما يمكنه مقارنة المعلومات عبر الوثائق. ويمكن أن يؤدي ذلك إلى تحسين استرجاع بيانات المستوى 2 والتحقق من صحتها، مما يدعم تحليل المخاطر واتخاذ القرارات بشكل أفضل ويعزز الجودة والشفافية الإجمالية للنظام العالمي لرموز تعريف المشاركين (LEI).
في الواقع، تستخدم GLEIF بالفعل الاستخراج القائم على الذكاء الاصطناعي لاسترداد بيانات العلاقات من التقارير السنوية وتحويلها إلى تنسيق منظم. وهذا يمكّن GLEIF من مراجعة وتأكيد معلومات العلاقات الحالية في دليل معرّفات الكيانات القانونية الدولي، أو إجراء تحديثات عند الحاجة، خارج عملية التجديد السنوية. ونتيجة لذلك، يمكن الحفاظ على بيانات العلاقات أكثر حداثة وموثوقية بمرور الوقت.
التطورات في "Transparency Fabric" – وهي مبادرة مشتركة أطلقتها GLEIF و وOpen Ownership وOpenSanctions – في عام 2025، أدخلت أيضًا استخدام نماذج اللغة الكبيرة (LLMs) لاستخراج وتحليل المعلومات من المستندات غير المنظمة لرسم خرائط أفضل لهياكل الملكية المعقدة ودعم ربط معرفات الكيانات القانونية (LEI) ببيانات الملكية الفعلية والعقوبات.
كيف تعمل
تحدد العملية الآلية جميع الشركات التابعة للشركات الأم في تقرير سنوي بصيغة PDF باستخدام عملية متعددة الخطوات تعتمد على نماذج اللغة الكبيرة (LLM):
أولاً، تراجع الذكاء الاصطناعي التقرير وتحدد الشركات التابعة المحتملة بناءً على التعريفات والأمثلة المقدمة. ثم تتحقق من نتائجها لتحديد الثغرات المحتملة أو الشركات التابعة المفقودة أو الإدخالات التي قد تكون أُدرجت بشكل غير صحيح.
بعد هذا المراجعة، يتم تنقيح النتائج لتصبح قائمة نهائية بالصيغة المطلوبة. ويشمل ذلك إزالة النتائج الإيجابية الخاطئة، وإضافة أي شركات تابعة فاتت، والتحقق من مراجع الصفحات ذات الصلة، وتوحيد التفاصيل مثل معلومات الولاية القضائية أو البلد.
أخيرًا، يمكن مقارنة القائمة التي أنشأها الذكاء الاصطناعي بقائمة مستخرجة يدويًا لتقييم الدقة والاكتمال والجودة الإجمالية.
يوضح هذا كيف يمكن للذكاء الاصطناعي المساعدة في تسريع استخراج بيانات الشركات التابعة من مستندات PDF المعقدة. وفي الوقت نفسه، يظل الجمع بين الإشراف البشري أمرًا مهمًا للتحقق من صحة النتائج وتحسين الجودة وضمان موثوقية بيانات العلاقات النهائية.
استخدام بيانات LEI الموثوقة لتحسين الذكاء الاصطناعي نفسه
بينما يمكن أن يساعد الذكاء الاصطناعي في العثور على بيانات العلاقات من المستوى 2 والتحقق منها، يمكن لبيانات LEI الموثوقة، بدورها، تعزيز استخدام أساليب الذكاء الاصطناعي في هذه المهمة.
استخدمت GLEIF بيانات LEI الحالية والتقارير السنوية لتحسين المطالبات باستخدام نهج GEPA، أو تطور المطالبات الانعكاسية الجينية لباريتو. بدلاً من التخمين بشأن المطالبة التي قد تحقق أفضل أداء، يستخدم GEPA البيانات المصنفة وردود الفعل البشرية لتطوير متغيرات أقوى للمطالبات، واختبارها مقابل أمثلة معروفة، والاحتفاظ بأفضل التوازنات أداءً.
يحول هذا النهج تطوير الذكاء الاصطناعي من التجريب إلى التحسين القابل للقياس. على سبيل المثال، حسّن موجه محسّن بواسطة GEPA الدقة القابلة للقياس لمعلومات العلاقة المسترجعة. والأمر الأكثر إثارة للاهتمام هو أن نموذجًا أصغر وأرخص كان أداؤه أفضل من نموذج أكبر وأغلى بعد التحسين. وهذا يوضح أن جودة البيانات والتحسين المنظم غالبًا ما يكونان أكثر أهمية من استخدام نموذج أكبر. ببساطة، المدخلات الأفضل تنتج مخرجات أفضل.
الجمع بين ابتكارات الذكاء الاصطناعي وأسس البيانات الموثوقة
إن النتيجة الأكثر قيمة لاستخراج بيانات العلاقات المدفوعة بالذكاء الاصطناعي هي القدرة على تحويل الإفصاحات المجزأة إلى معلومات استخباراتية موثوقة ومنظمة وقابلة للتنفيذ – مما يمكّن المؤسسات من اتخاذ قرارات أكثر استنارة عبر الاقتصاد العالمي.
ومع ذلك، تظل الأطر الموثوقة والحوكمة والمعرفات الموحدة ضرورية لضمان موثوقية هذه الرؤى وقابليتها للاستخدام. ومن خلال الجمع بين ابتكارات الذكاء الاصطناعي والأسس الموثوقة للنظام العالمي لرموز تعريف الكيانات (LEI)، تتاح فرصة لتعزيز جودة وتغطية وقابلية استخدام بيانات الملكية والعلاقات على نطاق واسع.
فإذا رغبتم في التعليق على منشور في المدوّنة، يُرجى زيارة خاصيّة المدوّنة على موقع GLEIF الإلكتروني باللغة الإنجليزية لنشر تعليقكم. ويُرجى تعريف أنفسكم بذكر الاسم الأول واسم العائلة. سوف يظهر اسمكم بجانب تعليقكم. لن تُنشر عناوين البريد الإلكتروني. يرجى الملاحظة بأنه من خلال الدخول إلى منتدى المناقشة أو المساهمة فيه فأنتم توافقون على الالتزام بشروط سياسة التدوين لدى GLEIF، ولذا يرجى قراءتها جيدًا.
تترأس زورنيتسا مانولوفا قسم إدارة جودة البيانات وفريق علوم البيانات في Global Legal Entity Identifier Foundation (GLEIF). منذ أبريل 2018، تتولى مسؤولية تعزيز وتحسين إطار عمل جودة البيانات ومراقبة البيانات الراسخ من خلال تقديم مناهج تحليل بيانات مبتكرة. في السابق، كانت زورنيتسا تتولى إدارة مشروعات تحليل بيانات الطب الشرعي في التحقيقات المالية الدولية في PwC Forensics. وتحمل دبلومة ألمانية في علوم الكمبيوتر مع التركيز على التعلم الآلي من جامعة فيليبس في ماربورغ.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
