Las traducciones de este sitio web a otros idiomas distintos del inglés se realizan mediante IA. No garantizamos la exactitud y no somos responsables de los errores o daños derivados del uso del contenido traducido. En caso de incoherencias o ambigüedades, la versión inglesa prevalecerá.
Sala de prensa y Medios
Blog de la GLEIF
Las traducciones de este sitio web a otros idiomas distintos del inglés se realizan mediante IA. No garantizamos la exactitud y no somos responsables de los errores o daños derivados del uso del contenido traducido. En caso de incoherencias o ambigüedades, la versión inglesa prevalecerá.
Transformar los datos en oportunidades: «Metric in Motion» — Cómo la IA puede reforzar la transparencia en la titularidad
Las organizaciones dependen cada vez más de los datos sobre relaciones para la Gestión de riesgos, la diligencia debida, el Cumplimiento normativo y la transparencia. En este blog, Zornitsa Manolova, directora de Calidad de datos y Ciencia de datos en GLEIF, analiza cómo la IA ofrece nuevas oportunidades para mejorar la calidad, la exhaustividad y la accesibilidad de la información fiable sobre la titularidad a gran escala.
Autor: Zornitsa Manolova
Fecha: 2026-06-08
Visualizaciones:
En una economía global cada vez más interconectada, la capacidad de las organizaciones para confiar en los datos y utilizarlos de forma eficaz es la base de la innovación, el crecimiento y la competitividad.
Un ecosistema de datos de alta calidad es un motor de cambio e innovación que permite a las organizaciones identificar y aprovechar nuevas oportunidades, mientras que una baja calidad de datos puede dar lugar a ineficiencias y a la exposición a riesgos normativos y de reputación.
Para contribuir a una mayor concienciación del sector sobre las iniciativas de Calidad de datos de GLEIF y su aplicación a diferentes sectores, esta nueva serie de entradas de blog explora las métricas clave incluidas en los informes.
Tema central de este mes: cómo la IA puede reforzar la transparencia de la propiedad.
A medida que las estructuras corporativas globales se vuelven más complejas, el acceso a datos fiables sobre la propiedad y las relaciones es cada vez más importante para la transparencia, la rendición de cuentas y el conocimiento de los riesgos. Estos datos, que incluyen las relaciones entre matrices y filiales, ayudan a las organizaciones a evaluar el riesgo, respaldar el cumplimiento normativo y tomar decisiones más informadas al mostrar cómo se relacionan las Entidades Legales.
Dentro del Sistema Global del Identificador de Entidades Legales, los datos de Nivel 2 proporcionan este contexto fundamental al identificar las estructuras corporativas de matrices y filiales, las conexiones entre sucursales y sedes centrales, y las relaciones entre fondos. A menudo descritos como la respuesta a la pregunta «quién pertenece a quién», los datos de Nivel 2 ayudan a revelar las estructuras que hay detrás de las Entidades Legales y refuerzan la confianza en los ecosistemas financieros y empresariales.
Comprender el valor de los datos de Nivel 2 en el Sistema Global de LEI
Una encuesta reciente realizada por el Comité de Supervisión Regulatoria (ROC) y la GLEIF destaca el valor de los datos de Nivel 2. Aproximadamente el 70 % de los encuestados informó que utiliza datos de Nivel 2, mientras que casi el 85 % afirmó que los considera datos de calidad. Los encuestados también confirmaron que los datos de nivel 2 ya están integrados en la toma de decisiones de sus organizaciones e indicaron que utilizan dichos datos para respaldar diversos procesos operativos y estratégicos, y muchos valoran especialmente las relaciones consolidadas con la sociedad matriz.
Estos resultados ponen de relieve una tendencia clave. A medida que aumenta la demanda de información fiable sobre la propiedad, resulta fundamental mantener datos de relaciones de alta calidad a gran escala.
La IA abre nuevas posibilidades para la extracción de datos de relaciones
Dado que la inteligencia artificial (IA) está transformando la forma en que las organizaciones gestionan y analizan los datos, están surgiendo nuevas oportunidades para satisfacer esta necesidad de mejorar aún más la calidad, la exhaustividad y la fiabilidad de los datos de relaciones.
Por ejemplo, ya existe una amplia disponibilidad de información valiosa sobre relaciones, pero a menudo es difícil acceder a ella porque se encuentra oculta en informes anuales y otras publicaciones corporativas. Los detalles de las sociedades matrices y filiales pueden aparecer en notas al pie, tablas, notas a los estados financieros o secciones narrativas. Estas divulgaciones suelen estar fragmentadas, tener un formato inconsistente y ser difíciles de revisar manualmente a gran escala, lo que dificulta su integración en conjuntos de datos estructurados.
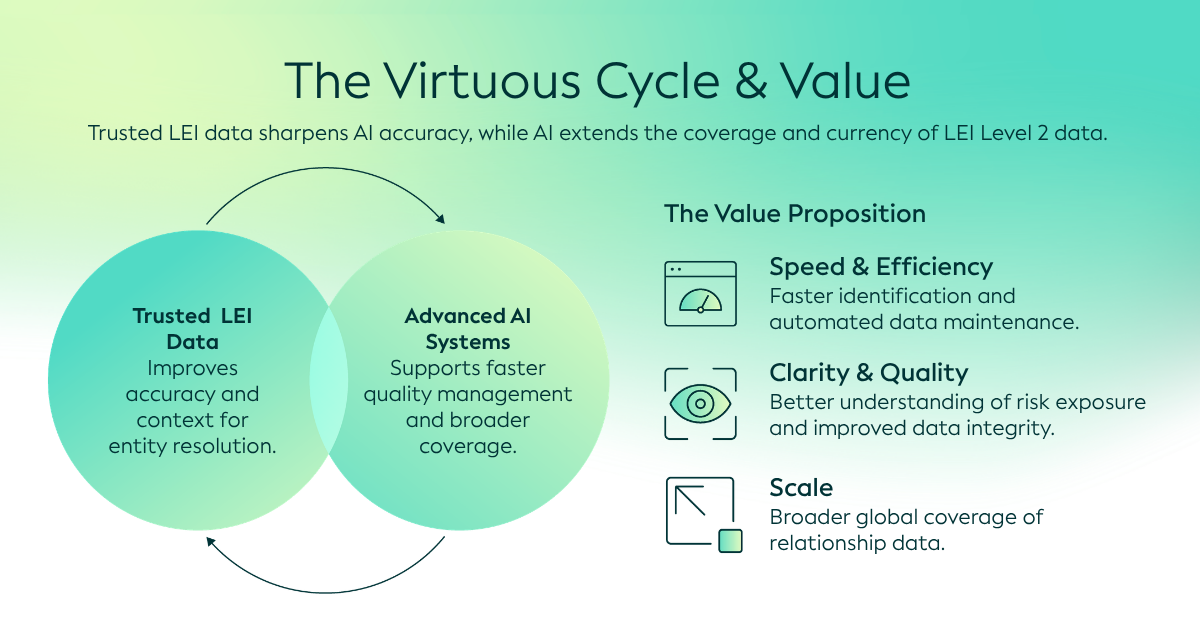
La extracción basada en IA ofrece una forma práctica de desbloquear esta información oculta. Al identificar, interpretar y estructurar los detalles de propiedad a partir de informes anuales y otros documentos PDF complejos, la IA puede ayudar a transformar la información no estructurada en datos de relaciones estructurados. También puede comparar la información entre documentos. Esto puede mejorar la recuperación y validación de los datos de Nivel 2, lo que favorece un mejor análisis de riesgos y la toma de decisiones, y mejora la calidad y transparencia generales del Sistema Global de LEI.
De hecho, la GLEIF ya está utilizando la extracción basada en IA para recuperar los datos de relaciones de los informes anuales y convertirlos a un formato estructurado. Esto permite a la GLEIF revisar y confirmar la información de relaciones existente en el Índice Global del LEI, o activar actualizaciones cuando sea necesario, al margen del proceso de renovación anual. Como resultado, los datos de relaciones pueden mantenerse más actualizados y fiables a lo largo del tiempo.
Los avances en Transparency Fabric —una iniciativa conjunta presentada por la GLEIF, Open Ownership y OpenSanctions — en 2025 también introdujeron el uso de grandes modelos de lenguaje (LLM) para extraer y analizar información de documentos no estructurados con el fin de mapear mejor las estructuras de propiedad complejas y facilitar la vinculación de los LEI con datos sobre la titularidad real y las sanciones.
Cómo funciona
El proceso automatizado identifica todas las filiales de las sociedades matrices en un informe anual en formato PDF mediante un proceso de varios pasos basado en un LLM:
En primer lugar, la IA revisa el informe e identifica posibles filiales basándose en las definiciones y ejemplos proporcionados. A continuación, comprueba sus propios resultados para identificar posibles lagunas, filiales que faltan o entradas que puedan haberse incluido incorrectamente.
Tras esta revisión, los resultados se refinan en una lista final con el formato requerido. Esto incluye eliminar falsos positivos, añadir cualquier filial omitida, comprobar las referencias de página pertinentes y estandarizar detalles como la jurisdicción o la información del país.
Por último, la lista generada por la IA se puede comparar con una lista extraída manualmente para evaluar la precisión, la exhaustividad y la calidad general.
Esto demuestra cómo la IA puede ayudar a acelerar la extracción de datos de filiales a partir de documentos PDF complejos. Al mismo tiempo, la combinación con la supervisión humana sigue siendo importante para validar los resultados, mejorar la calidad y garantizar que los datos finales sobre relaciones sean fiables.
Uso de datos LEI fiables para mejorar la propia IA
Si bien la IA puede ayudar a encontrar y verificar datos de relaciones de nivel 2, los datos LEI fiables pueden, a su vez, mejorar el uso de los métodos de IA para esta tarea.
La GLEIF ha utilizado datos LEI existentes e informes anuales para optimizar las indicaciones mediante el enfoque GEPA, o Evolución Genética de Indicaciones Reflectivas de Pareto. En lugar de adivinar qué indicación podría funcionar mejor, GEPA utiliza datos etiquetados y comentarios humanos para desarrollar variantes de indicaciones más sólidas, probarlas con ejemplos conocidos y conservar las soluciones de compromiso que mejor funcionan.
Este enfoque traslada el desarrollo de la IA de la experimentación a la mejora cuantificable. Por ejemplo, una indicación mejorada con GEPA aumentó la precisión medible de la información de relaciones recuperada. Y lo que es aún más interesante, un modelo más pequeño y económico funcionó mejor que uno más grande y costoso tras la optimización. Esto demuestra que la calidad de los datos y la optimización estructurada suelen ser más importantes que el uso de un modelo más grande. En pocas palabras, mejores entradas generan mejores resultados.
Combinar la innovación en IA con bases de datos fiables
El resultado más valioso de la extracción de datos de relaciones impulsada por la IA es la capacidad de transformar divulgaciones fragmentadas en inteligencia de relaciones fiable, estructurada y procesable, lo que permite a las organizaciones tomar decisiones más informadas en toda la economía global.
Sin embargo, los marcos fiables, la Gobernanza y los identificadores estandarizados siguen siendo esenciales para garantizar que estos conocimientos sean fiables y utilizables. Al combinar la innovación en IA con los cimientos fiables del Sistema Global de LEI, existe la oportunidad de reforzar la calidad, la cobertura y la usabilidad de los datos de propiedad y relaciones a gran escala.
Si quiere hacer comentarios sobre algún artículo del blog, identifíquese con su nombre y sus apellidos. Su nombre aparecerá junto a su comentario. No se publicarán las direcciones de correo electrónico. Tenga en cuenta que, mediante su acceso al foro de debate o su contribución en él, acuerda cumplir los términos de las Directrices sobre los blogs de la GLEIF, por lo que le pedimos que los lea detenidamente.
Zornitsa Manolova dirige el equipo de Gestión de la Calidad de los Datos y Ciencia de la Global Legal Entity Identifier Foundation (GLEIF). Desde abril de 2018, se encarga de mejorar y perfeccionar el marco establecido para la calidad de los datos y la gobernanza de los datos mediante la introducción de enfoques innovadores de análisis de datos. Anteriormente, Zornitsa dirigió proyectos de análisis de datos forenses en investigaciones financieras internacionales en PwC Forensics. Es licenciada en Ciencias de la Computación, con la especialidad de Aprendizaje Automático, por la Universidad Philipps en Marburg, Alemania.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
