Bu web sitesindeki İngilizce dışındaki çeviriler yapay zeka tarafından desteklenmektedir. Doğruluğu garanti etmiyoruz ve çevrilmiş içeriğin kullanımından kaynaklanan herhangi bir hata veya zarardan sorumlu değiliz. Tutarsızlık veya belirsizlik durumunda, İngilizce versiyon geçerli olacaktır.
Haber Odası ve Medya
GLEIF Blog
Bu web sitesindeki İngilizce dışındaki çeviriler yapay zeka tarafından desteklenmektedir. Doğruluğu garanti etmiyoruz ve çevrilmiş içeriğin kullanımından kaynaklanan herhangi bir hata veya zarardan sorumlu değiliz. Tutarsızlık veya belirsizlik durumunda, İngilizce versiyon geçerli olacaktır.
Verileri Fırsatlara Dönüştürmek: Hareket Halindeki Metrikler – Yapay Zeka Sahiplik Şeffaflığını Nasıl Güçlendirebilir?
Kuruluşlar, Risk Yönetimi, durum tespiti, Uyum ve Şeffaflık için giderek daha fazla ilişki verilerine güveniyor. Bu blog yazısında, GLEIF Veri Kalitesi Yönetimi ve Veri Bilimi Başkanı Zornitsa Manolova, yapay zekanın güvenilir mülkiyet bilgilerinin kalitesini, eksiksizliğini ve erişilebilirliğini büyük ölçekte iyileştirmek için nasıl yeni fırsatlar sunduğunu inceliyor.
Yazar: Zornitsa Manolova
Tarih: 2026-06-08
Görünümler:
Giderek daha fazla birbirine bağlı hale gelen küresel ekonomide, kuruluşların verilere güvenme ve bunları etkili bir şekilde kullanma becerisi, inovasyon, büyüme ve rekabet gücünün temelini oluşturur.
Yüksek kaliteli bir veri ekosistemi, kuruluşların yeni fırsatları belirleyip bunlardan yararlanmasını sağlayan bir değişim ve inovasyon itici gücüdür; buna karşılık, düşük Veri Kalitesi verimsizliğe yol açabilir ve düzenleyici ve itibar risklerine maruz kalmaya neden olabilir.
GLEIF'in Veri Kalitesi girişimleri ve bunların farklı sektörlere uygulanması konusunda sektörde daha geniş bir farkındalık yaratmak amacıyla, bu yeni blog serisi raporlarda yer alan temel ölçütleri incelemektedir.
Bu ayın odak noktası: AI'nın sahiplik şeffaflığını nasıl güçlendirebileceği.
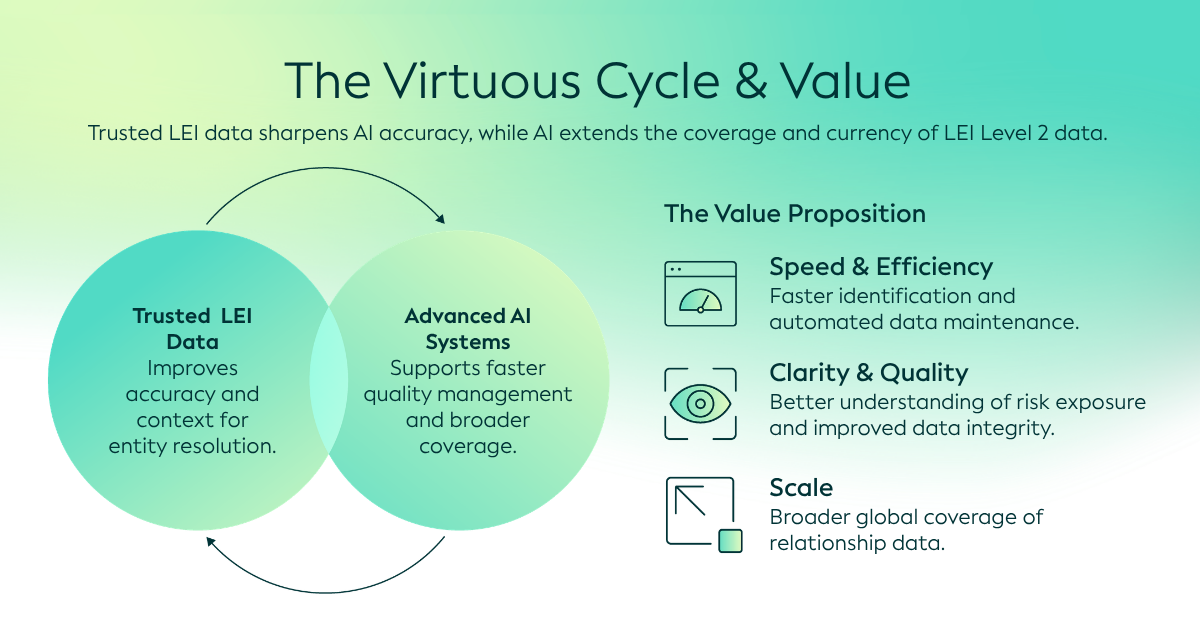
Küresel kurumsal yapılar giderek daha karmaşık hale geldikçe, şeffaflık, hesap verebilirlik ve risk analizi açısından güvenilir mülkiyet ve ilişki verilerine erişim giderek daha önemli hale gelmektedir. Ana şirket ve bağlı şirket ilişkilerini içeren bu veriler, tüzel kişiliklerin birbirleriyle nasıl bağlantılı olduğunu göstererek kuruluşların riski değerlendirmesine, uyumu desteklemesine ve daha bilinçli kararlar almasına yardımcı olur.
Global Tüzel Kişi Kimlik Kodu Sistemi içinde, Düzey 2 verileri ana ve bağlı şirket yapılarını, şube-merkez bağlantılarını ve fon ilişkilerini tanımlayarak bu kritik bağlamı sağlar. Genellikle "kim kime aittir" sorusuna cevap olarak tanımlanan Düzey 2 verileri, tüzel kişiliklerin arkasındaki yapıları ortaya çıkarmaya yardımcı olur ve finansal ve iş ekosistemleri genelinde güveni güçlendirir.
Küresel LEI Sisteminde Seviye 2 Verilerinin Değerini Anlamak
Düzenleyici Gözetim Komitesi (ROC) ve GLEIF tarafından yakın zamanda yapılan bir anket, Seviye 2 verilerinin değerini vurgulamaktadır. Ankete katılanların yaklaşık %70'i Seviye 2 verilerini kullandığını bildirirken, yaklaşık %85'i bu verileri kaliteli veriler olarak değerlendirdiğini belirtmiştir. Ankete katılanlar ayrıca, Seviye 2 verilerinin halihazırda kuruluşlarının karar alma süreçlerine entegre olduğunu doğruladı ve çeşitli operasyonel ve stratejik süreçleri desteklemek için Seviye 2 verilerini kullandıklarını bildirdi; bunların çoğu özellikle konsolide ana şirket ilişkilerine değer veriyordu.
Bu bulgular önemli bir eğilimi ortaya koymaktadır. Güvenilir sahiplik bilgisine olan talep arttıkça, yüksek kaliteli ilişki verilerini büyük ölçekte korumak kritik önem taşımaktadır.
AI, İlişki Verilerinin Çıkarılması için Yeni Olanaklar Sunuyor
Yapay zeka (AI), kuruluşların verileri yönetme ve analiz etme şeklini dönüştürürken, ilişki verilerinin kalitesini, eksiksizliğini ve güvenilirliğini daha da artırma ihtiyacını karşılamak için yeni fırsatlar ortaya çıkmaktadır.
Örneğin, değerli ilişki bilgileri halihazırda yaygın olarak mevcuttur, ancak yıllık raporlar ve diğer kurumsal açıklamaların içinde gömülü oldukları için genellikle erişilmesi zordur. Ana şirket ve bağlı şirket bilgileri dipnotlarda, tablolarda, mali tablo notlarında veya açıklayıcı bölümlerde yer alabilir. Bu açıklamalar genellikle parçalı, tutarsız bir biçimde düzenlenmiş ve büyük ölçekte manuel olarak incelenmesi zor olduğundan, yapılandırılmış veri kümelerine entegre edilmesi zordur.
AI destekli veri çıkarma, bu gizli bilgilere ulaşmak için pratik bir yol sunar. Yıllık raporlardan ve diğer karmaşık PDF belgelerinden sahiplik ayrıntılarını belirleyerek, yorumlayarak ve yapılandırarak AI, yapılandırılmamış bilgileri yapılandırılmış ilişki verilerine dönüştürmeye yardımcı olabilir. Ayrıca, belgeler arasındaki bilgileri karşılaştırabilir. Bu, Seviye 2 verilerinin alınmasını ve doğrulanmasını iyileştirerek daha iyi risk analizi ve karar vermeyi destekleyebilir ve Küresel LEI Sisteminin genel kalitesini ve şeffaflığını artırabilir.
Aslında GLEIF, yıllık raporlardan ilişki verilerini almak ve bunları yapılandırılmış biçime dönüştürmek için halihazırda yapay zeka tabanlı veri çıkarma yöntemini kullanmaktadır. Bu, GLEIF’in yıllık yenileme süreci dışında da Global LEI Dizini’ndeki mevcut ilişki bilgilerini gözden geçirip onaylamasına veya gerektiğinde güncellemeleri tetiklemesine olanak tanır. Sonuç olarak, ilişki verileri zaman içinde daha güncel ve güvenilir tutulabilir.
Transparency Fabric – GLEIF, Open Ownership ve OpenSanctions tarafından başlatılan ortak bir girişim olan Transparency Fabric'teki gelişmeler, 2025 yılında karmaşık sahiplik yapılarını daha iyi haritalandırmak ve LEI'lerin gerçek sahiplik ve yaptırım verileriyle ilişkilendirilmesini desteklemek amacıyla yapılandırılmamış belgelerden bilgi çıkarmak ve analiz etmek için Büyük Dil Modelleri'nin (LLM'ler) kullanımını da getirmiştir.
Nasıl Çalışır
Otomatik süreç, LLM çok adımlı bir süreç kullanarak yıllık rapor PDF'sindeki ana şirketlerin tüm bağlı şirketlerini tanımlar:
İlk olarak, yapay zeka raporu inceler ve sağlanan tanımlar ile örneklere dayanarak olası bağlı şirketleri belirler. Ardından, kendi sonuçlarını kontrol ederek potansiyel boşlukları, eksik bağlı şirketleri veya yanlış dahil edilmiş olabilecek girişleri tespit eder.
Bu incelemenin ardından, sonuçlar gerekli formatta nihai bir liste haline getirilir. Bu işlem, yanlış pozitiflerin kaldırılmasını, eksik bağlı şirketlerin eklenmesini, ilgili sayfa referanslarının kontrol edilmesini ve yargı yetkisi veya ülke bilgileri gibi ayrıntıların standartlaştırılmasını içerir.
Son olarak, AI tarafından oluşturulan liste, doğruluk, eksiksizlik ve genel kaliteyi değerlendirmek için manuel olarak çıkarılan listeyle karşılaştırılabilir.
Bu, AI'nın karmaşık PDF belgelerinden bağlı şirket verilerinin çıkarılmasını nasıl hızlandırabileceğini göstermektedir. Aynı zamanda, sonuçları doğrulamak, kaliteyi artırmak ve nihai ilişki verilerinin güvenilir olmasını sağlamak için insan denetimini birleştirmek önemini korumaktadır.
Güvenilir LEI Verilerini Kullanarak AI'yı Geliştirmek
AI, Seviye 2 ilişki verilerini bulmaya ve kontrol etmeye yardımcı olabilirken, güvenilir LEI verileri de bu görev için AI yöntemlerinin kullanımını geliştirebilir.
GLEIF, mevcut LEI verilerini ve yıllık raporları kullanarak GEPA (Genetic Pareto Reflective Prompt Evolution) yaklaşımını uygulayarak komut istemlerini optimize etmiştir. GEPA, hangi komut isteminin en iyi performansı göstereceğini tahmin etmek yerine, etiketli verileri ve insan geri bildirimlerini kullanarak daha güçlü komut istemi varyantları geliştirir, bunları bilinen örneklerle test eder ve en iyi performansı gösteren denge noktalarını korur.
Bu yaklaşım, AI geliştirmeyi deneysel aşamadan ölçülebilir iyileştirme aşamasına taşır. Örneğin, GEPA ile geliştirilmiş bir komut, alınan ilişki bilgilerinin ölçülebilir doğruluğunu artırdı. Daha da ilginç olanı, optimizasyondan sonra daha küçük ve daha ucuz bir modelin, daha büyük ve daha pahalı bir modelden daha iyi performans göstermesidir. Bu, yüksek kaliteli verilerin ve yapılandırılmış optimizasyonun genellikle daha büyük bir model kullanmaktan daha önemli olduğunu göstermektedir. Basitçe söylemek gerekirse, daha iyi girdiler daha iyi çıktılar yaratır.
AI İnovasyonunu Güvenilir Veri Temelleriyle Birleştirme
AI odaklı ilişki verisi çıkarmanın en değerli sonucu, parçalı açıklamaları güvenilir, yapılandırılmış ve eyleme geçirilebilir ilişki istihbaratına dönüştürme yeteneğidir; bu da kuruluşların küresel ekonomi genelinde daha bilinçli kararlar almasını sağlar.
Ancak, bu içgörülerinin güvenilir ve kullanılabilir olmasını sağlamak için güvenilir çerçeveler, yönetim ve standartlaştırılmış tanımlayıcılar hâlâ çok önemlidir. AI inovasyonunu Global LEI Sisteminin güvenilir temelleriyle birleştirerek, sahiplik ve ilişki verilerinin kalitesini, kapsamını ve kullanılabilirliğini büyük ölçekte güçlendirme fırsatı doğar.
Bir blog yazısını yorumlamak isterseniz, lütfen yorumunuzu göndermek için İngilizce dilindeki GLEIF web sitesi blog işlevini ziyaret edin. Lütfen kendinizi adınız ve soyadınız ile tanıtın. Adınız, yorumunuzun yanında görünecektir. E-posta adresleri yayımlanmayacaktır. Lütfen tartışma panosuna erişerek veya katkıda bulunarak, GLEIF Bloglama Politikası şartlarına uymayı kabul ettiğinizi dikkate alın, bu nedenle lütfen dikkatlice okuyun.
Zornitsa Manolova, Global Legal Entity Identifier Foundation'da (GLEIF) Veri Kalitesi Yönetimi ve Veri Bilimi ekibini yönetmektedir. Nisan 2018'den beri yenilikçi veri analizi yaklaşımları kullanmaya başlayarak yerleşik veri kalitesi ve veri yönetimi çerçevesi geliştirip iyileştirmekten sorumludur. Zornitsa daha önce PwC Adli Hizmetler'de uluslararası finansal soruşturmalarda adli veri analizi projeleri yönetti. Marburg'daki Philipps Üniversitesinden Makine Öğrenimi odak noktasına sahip Alman Bilgisayar Bilimleri Diplomasına sahiptir.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
