Les traductions de ce site web dans des langues autres que l'anglais sont générées par l'IA. Nous ne garantissons pas l'exactitude et ne sommes pas responsables des erreurs ou dommages résultant de l'utilisation du contenu traduit. En cas d'incohérences ou d'ambiguïtés, la version anglaise prévaut.
Salle des nouvelles & Médias
Le blog de la GLEIF
Les traductions de ce site web dans des langues autres que l'anglais sont générées par l'IA. Nous ne garantissons pas l'exactitude et ne sommes pas responsables des erreurs ou dommages résultant de l'utilisation du contenu traduit. En cas d'incohérences ou d'ambiguïtés, la version anglaise prévaut.
Transformer les données en opportunités : Metric in Motion – Comment l'IA peut renforcer la transparence en matière de propriété
Les organisations s'appuient de plus en plus sur les données relationnelles pour la gestion des risques, la diligence raisonnable, la conformité et la transparence. Dans cet article, Zornitsa Manolova, responsable de la gestion de la qualité des données et de la science des données à la GLEIF, explore comment l'IA offre de nouvelles opportunités pour améliorer la qualité, l'exhaustivité et l'accessibilité d'informations fiables sur la propriété à grande échelle.
Auteur: Zornitsa Manolova
Date: 2026-06-08
Vues:
Dans une économie mondiale de plus en plus interconnectée, la capacité des organisations à faire confiance aux données et à les utiliser efficacement constitue le fondement de l’innovation, de la croissance et de la compétitivité.
Un écosystème de données de haute qualité est un moteur de changement et d’innovation qui permet aux organisations d’identifier et de saisir de nouvelles opportunités, tandis qu’une faible qualité des données peut entraîner des inefficacités et exposer les organisations à des risques réglementaires et de réputation.
Afin de mieux faire connaître au secteur les initiatives de la GLEIF en matière de qualité des données et leur application à différents secteurs, cette nouvelle série d’articles explore les indicateurs clés inclus dans les rapports.
Thème du mois : comment l’IA peut renforcer la transparence en matière de propriété.
À mesure que les structures d’entreprise mondiales se complexifient, l’accès à des données fiables sur la propriété et les relations devient de plus en plus important pour la transparence, la responsabilité et la compréhension des risques. Ces données, qui incluent les relations entre sociétés mères et filiales, aident les organisations à évaluer les risques, à garantir la Conformité et à prendre des décisions plus éclairées en montrant comment les entités légales sont liées.
Au sein du Système d'identification international pour les entités légales, les données de niveau 2 fournissent ce contexte essentiel en identifiant les structures des sociétés mères et filiales, les liens entre succursales et sièges sociaux, ainsi que les relations entre fonds. Souvent décrites comme répondant à la question « qui détient qui », les données de niveau 2 aident à révéler les structures sous-jacentes aux entités légales et renforcent la confiance au sein des écosystèmes financiers et commerciaux.
Comprendre la valeur des données de niveau 2 dans le système LEI mondial
Une récente enquête menée par le Comité de surveillance réglementaire (ROC) et la GLEIF met en évidence la valeur des données de niveau 2. Environ 70 % des personnes interrogées ont déclaré utiliser les données de niveau 2, tandis que près de 85 % ont indiqué qu’elles les considéraient comme des données de qualité. Les répondants ont également confirmé que les données de niveau 2 sont déjà intégrées dans le processus décisionnel de leur organisation et ont indiqué les utiliser pour soutenir divers processus opérationnels et stratégiques, beaucoup d’entre eux accordant une importance particulière aux relations consolidées avec la société mère.
Ces résultats mettent en évidence une tendance majeure. À mesure que la demande d’informations fiables sur l’actionnariat augmente, il est essentiel de maintenir des données de relations de haute qualité à grande échelle.
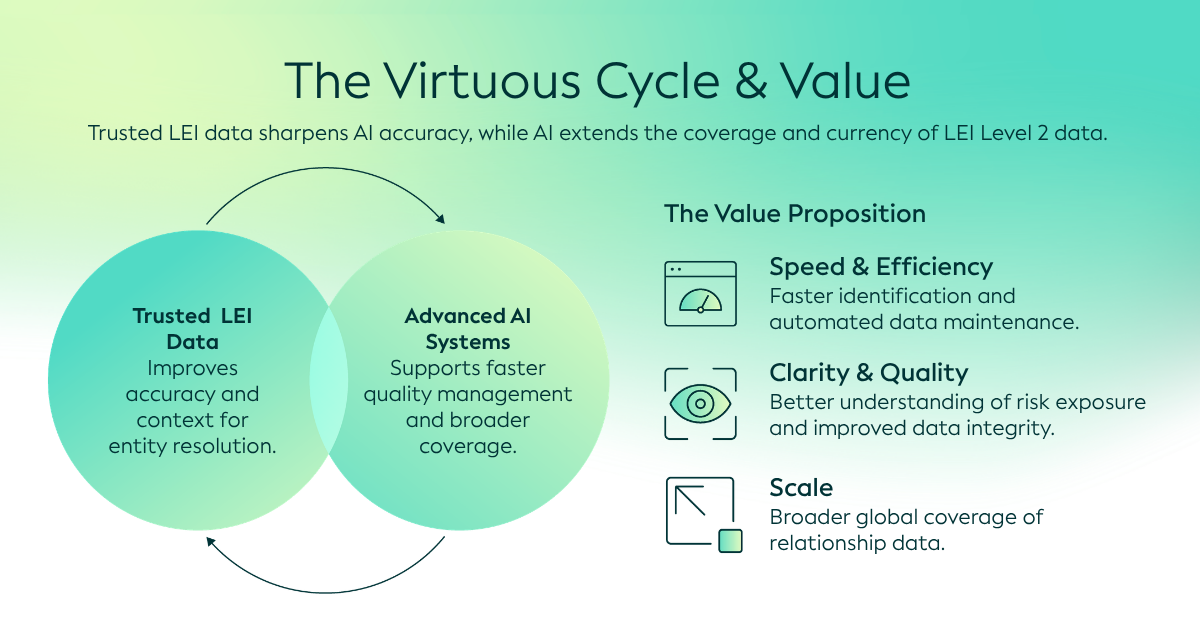
L'IA ouvre de nouvelles perspectives pour l'extraction de données relationnelles
L'intelligence artificielle (IA) transformant la manière dont les organisations gèrent et analysent les données, de nouvelles opportunités émergent pour répondre à ce besoin d'améliorer encore la qualité, l'exhaustivité et la fiabilité des données relationnelles.
Par exemple, des informations précieuses sur les relations sont déjà largement disponibles, mais elles sont souvent difficiles d'accès car enfouies dans les rapports annuels et autres publications d'entreprise. Les détails concernant les sociétés mères et les filiales peuvent apparaître dans des notes de bas de page, des tableaux, des notes annexes aux états financiers ou des sections narratives. Ces informations sont souvent fragmentées, présentées de manière incohérente et difficiles à examiner manuellement à grande échelle, ce qui rend leur intégration dans des ensembles de données structurés particulièrement complexe.
L'extraction basée sur l'IA offre un moyen pratique de mettre à jour ces informations cachées. En identifiant, en interprétant et en structurant les détails relatifs à la propriété à partir des rapports annuels et d'autres documents PDF complexes, l'IA peut aider à transformer des informations non structurées en données structurées sur les relations. Elle peut également comparer les informations entre différents documents. Cela peut améliorer la récupération et la validation des données de niveau 2, favorisant ainsi une meilleure analyse des risques et une prise de décision plus éclairée, tout en renforçant la qualité et la transparence globales du Système LEI mondial.
En effet, la GLEIF utilise déjà l’extraction basée sur l’IA pour extraire les données de relations des rapports annuels et les convertir en un format structuré. Cela permet à la GLEIF d’examiner et de confirmer les informations de relations existantes dans le Répertoire mondial des LEI, ou de déclencher des mises à jour si nécessaire, en dehors du processus de renouvellement annuel. En conséquence, les données de relations peuvent être maintenues plus à jour et plus fiables au fil du temps.
Les avancées de la « Transparency Fabric » – une initiative conjointe lancée par la GLEIF, Open Ownership et OpenSanctions – a également introduit en 2025 l’utilisation de grands modèles linguistiques (LLM) pour extraire et analyser des informations à partir de documents non structurés, afin de mieux cartographier les structures de propriété complexes et de faciliter l’appariement des LEI avec les données sur la propriété effective et les sanctions.
Fonctionnement
Le processus automatisé identifie toutes les filiales des sociétés mères dans un rapport annuel au format PDF à l’aide d’un processus LLM en plusieurs étapes :
Tout d’abord, l’IA examine le rapport et identifie les filiales potentielles sur la base des définitions et des exemples fournis. Elle vérifie ensuite ses propres résultats afin d’identifier d’éventuelles lacunes, des filiales manquantes ou des entrées qui auraient pu être incluses de manière erronée.
Après cet examen, les résultats sont affinés pour aboutir à une liste finale au format requis. Cela comprend la suppression des faux positifs, l'ajout des filiales manquantes, la vérification des références de pages pertinentes et la normalisation des détails tels que les informations sur la juridiction ou le pays.
Enfin, la liste générée par l'IA peut être comparée à une liste extraite manuellement afin d'évaluer l'exactitude, l'exhaustivité et la qualité globale.
Cela démontre comment l'IA peut contribuer à accélérer l'extraction des données sur les filiales à partir de documents PDF complexes. Parallèlement, il reste important de combiner cette approche avec une supervision humaine pour valider les résultats, améliorer la qualité et garantir la fiabilité des données finales sur les relations.
Utiliser des données LEI fiables pour améliorer l'IA elle-même
Si l'IA peut aider à trouver et à vérifier les données de relations de niveau 2, des données LEI fiables peuvent, à leur tour, améliorer l'utilisation des méthodes d'IA pour cette tâche.
La GLEIF a utilisé les données LEI existantes et les rapports annuels pour optimiser les invites à l’aide de l’approche GEPA (Genetic Pareto Reflective Prompt Evolution). Plutôt que de deviner quelle invite pourrait être la plus performante, la GEPA utilise des données étiquetées et des retours humains pour développer des variantes d’invites plus robustes, les tester par rapport à des exemples connus et retenir les compromis les plus performants.
Cette approche fait passer le développement de l'IA de l'expérimentation à une amélioration mesurable. Par exemple, une invite optimisée par GEPA a amélioré la précision mesurable des informations de relation récupérées. Plus intéressant encore, un modèle plus petit et moins coûteux a obtenu de meilleurs résultats qu’un modèle plus grand et plus coûteux après optimisation. Cela démontre que la qualité des données et une optimisation structurée importent souvent davantage que l’utilisation d’un modèle plus grand. En termes simples, de meilleures entrées créent de meilleurs résultats.
Combiner l'innovation en IA avec des bases de données fiables
Le résultat le plus précieux de l’extraction de données relationnelles pilotée par l’IA est la capacité à transformer des informations fragmentées en renseignements relationnels fiables, structurés et exploitables, permettant ainsi aux organisations de prendre des décisions plus éclairées à l’échelle de l’économie mondiale.
Pourtant, des cadres fiables, une Gouvernance et des identifiants normalisés restent essentiels pour garantir la fiabilité et l’utilité de ces informations. En combinant l’innovation en matière d’IA avec les bases fiables du Système mondial des codes LEI, il est possible de renforcer à grande échelle la qualité, la couverture et la facilité d’utilisation des données sur la propriété et les relations.
Si vous souhaitez commenter une publication sur le blog, veuillez vous identifier à l'aide de votre prénom et de votre nom. Votre nom apparaîtra à côté de votre commentaire. Aucune adresse e-mail ne sera publiée. Veuillez noter qu'en accédant ou en contribuant au forum de discussion, vous acceptez de respecter les conditions de la Politique de la GLEIF en matière de blog ; veuillez donc les lire attentivement.
Zornitsa Manolova dirige l’équipe chargée de la gestion de la qualité des données et de la science des données au sein de la Global Legal Entity Identifier Foundation {GLEIF}. Depuis avril 2018, elle a pour mission d’améliorer le cadre établi pour la qualité et la gouvernance des données en introduisant des méthodes d’analyse de données innovantes. Auparavant, Zornitsa est chargée de la gestion des projets d’analyse de données médico-légales dans le cadre d’enquêtes financières internationales chez PwC Forensics. Elle possède un diplôme allemand en informatique avec une spécialisation en apprentissage automatique de l’Université Philipps de Marbourg.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
