
LEI-Daten
GLEIF-Datenqualitätsmanagement
Datenqualität erfordert proaktive Maßnahmen
Proaktives Management
Zur Unterstützung der LEI-Vergabestellen stellt GLEIF die adäquaten und obligatorischen Prozesse sowie eine technische Schnittstelle für LEI-Vergabestellen bereit, mit denen LEI-Vergabestellen die Datenqualität eines LEIs und damit verbundene Referenzdaten überprüfen können. Dazu gehört die Prüfung auf Duplikate. Die LEI-Einträge müssen jeweils einzeln mittels der Programmierschnittstellen (APIs) des automatisierten Webservice überprüft werden: Daten-Governance Pre-Check und Prüfung auf Duplikate.
Daten-Governance Pre-Check

Die LEI-Vergabestellen müssen sämtliche neu vergebenen und aktualisierten LEI-Einträge an die Pre-Check-Funktionalität von GLEIF übermitteln, bevor sie diese im Global LEI Repository hochladen. Die Pre-Check-Funktionalität wendet die gleichen Datenqualitätsprüfungen an, die auf Tagesbasis für bereits veröffentlichte LEI-Einträge durchgeführt werden. Basierend auf den Pre-Check-Ergebnissen können LEI-Vergabestellen potenzielle Datenqualitätsprobleme beseitigen, bevor etwaige Unbeständigkeiten in den öffentlichen Datenpool gelangen. Abgesehen vom Prüfergebnis erhält der Antragstellende eine Erläuterung, die eine fokussierte und zügige Beseitigung des berichteten Problems ermöglicht.
Die verpflichtende Nutzung der Funktion durch LEI-Vergabestellen unterstützt den kontinuierlichen Verbesserungsprozess, erhöht die Qualität und steigert den Reifegrad der im Global LEI System enthaltenen Daten.
Prüfung auf Duplikate
Um Duplikate bei den Dateneinträgen zu vermeiden, werden neu angeforderte LEI-Codes und entsprechende Referenzdaten mit allen anderen Datensätzen im Global LEI Repository sowie mit LEI-Einträgen abgeglichen, die von anderen LEI-Vergabestellen an die Funktion „Prüfung auf Duplikate“ übermittelt, aber noch nicht vergeben wurden. Selbst wenn zwei verschiedene LEI-Vergabestellen von demselben Rechtsträger kontaktiert werden, können die LEI-Vergabestellen somit potenzielle Duplikate erkennen und sich mit ihren Kunden und untereinander abstimmen. Letztlich verhindert dieses Verfahren den Eintrag von Duplikaten im System.
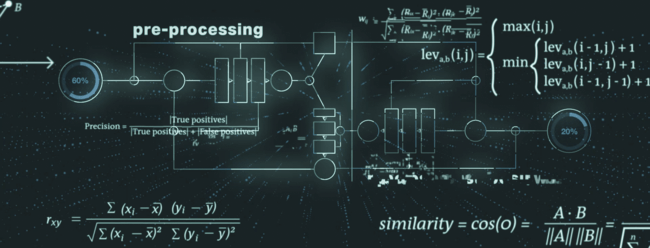
Das Verfahren zur Identifizierung von Duplikaten berücksichtigt mehrere Datenelemente des LEI-Eintrags und lässt sich in Vorverarbeitung, Kernalgorithmus und Nachverarbeitung unterteilen.
Während der Vorverarbeitung werden die Daten für die bevorstehenden Schritte aufbereitet. So werden die sogenannte schwache Token identifiziert und entsprechend Abhilfe geschaffen. Ein typisches Beispiel für einen schwachen Token ist die Rechtsform eines Rechtsträgers, die Teil des Namens eines Rechtsträgers sein kann. Die Rechtsform könnte dann normalisiert und harmonisiert werden, um die bestmöglichen Ergebnisse für die folgenden Verfahrensstufen sicherzustellen.
Das Kernstück der Funktion „Prüfung auf Duplikate“ besteht aus einer Eindeutigkeits- und einer Ausschließlichkeitsprüfung, bei denen modernste Algorithmen für Fuzzy-String-Matching (z. B. Levenshtein-Distanz, Kosinus-Ähnlichkeit, Monge-Elkan-Distanz) kombiniert werden.
Im Nachbearbeitungsschritt reduziert die Funktion „Prüfung auf Duplikate“ die Anzahl der falsch-positiven Ergebnisse durch zusätzliche Prüfungen und eine spezielle Behandlung von sekundären Datenelementen (z. B. Gerichtsbarkeit, Rechtsträgerkategorie).
Relevante Dateien zum Herunterladen
Herunterladen als PDF: Wörterbuch für Prüfung auf Duplikate v1.2 (Check for Duplicates Dictionary v1.2)