Übersetzungen dieser Website in andere Sprachen als Englisch werden von KI unterstützt. Wir garantieren keine Genauigkeit und haften nicht für Fehler oder Schäden, die sich aus der Nutzung der übersetzten Inhalte ergeben. Im Falle von Unstimmigkeiten oder Unklarheiten gilt die englische Version als maßgebend.
Newsroom & Medien
GLEIF-Blogbeiträge
Übersetzungen dieser Website in andere Sprachen als Englisch werden von KI unterstützt. Wir garantieren keine Genauigkeit und haften nicht für Fehler oder Schäden, die sich aus der Nutzung der übersetzten Inhalte ergeben. Im Falle von Unstimmigkeiten oder Unklarheiten gilt die englische Version als maßgebend.
Strategische Trends in der Datenqualität: Metric in Motion - Ein KI-gestützter Ansatz für die Datenqualität
Hochwertige Daten sind mehr als nur ein Maßstab - sie sind eine strategische Notwendigkeit für globales Vertrauen, Compliance und Interoperabilität. In diesem Blog untersucht Zornitsa Manolova, Leiterin des Datenqualitätsmanagements und der Datenwissenschaft bei GLEIF, wie KI dabei hilft, Datenqualitätsprüfungen zu verstärken, um eine transparentere globale Wirtschaft zu schaffen.
Autor: Zornitsa Manolova
Datum: 2026-02-06
Ansichten:
In einer zunehmend vernetzten globalen Wirtschaft ist die Fähigkeit von Unternehmen, Daten zu vertrauen und effektiv zu nutzen, die Grundlage für Innovation, Wachstum und Wettbewerbsfähigkeit.
Ein qualitativ hochwertiges Datenökosystem ist ein Motor für Veränderungen und Innovationen, der es Unternehmen ermöglicht, neue Chancen zu erkennen und zu nutzen, während eine niedrige Datenqualität zu Ineffizienzen und Risiken für Regulierung und Reputation führen kann.
GLEIF setzt sich für die Optimierung der Qualität, Zuverlässigkeit und Nutzbarkeit von LEI-Daten ein. Seit 2017 werden monatliche Berichte veröffentlicht, um die im globalen LEI-System erreichte Gesamtdatenqualität transparent darzustellen.
Um das Verständnis und das Bewusstsein der Branche für die Datenqualitätsinitiativen von GLEIF zu fördern, werden in dieser neuen Blogserie die in den Berichten enthaltenen Schlüsselmetriken untersucht.
Im Blog dieses Monats geht es darum, wie KI zur Verbesserung der Datenqualitätsprüfungen beiträgt.
Die Sicherstellung zuverlässiger LEI-Daten auf globaler Ebene erfordert eine einheitliche Auslegung der regulatorischen und politischen Anforderungen. Da sich diese Anforderungen weiterentwickeln und immer komplexer werden, stärkt KI die Fähigkeiten von GLEIF, eine skalierbare Qualitätssicherung zu unterstützen und gleichzeitig sicherzustellen, dass Transparenz und Governance weiterhin im Mittelpunkt stehen.
Von Richtlinienanforderungen zu Datenqualitätsprüfungen
Das Regulatory Oversight Committee (ROC) legt die Geschäftsregeln und Richtlinien für das Global LEI System fest. Diese Anforderungen werden dann beschrieben und durch die Zustandsübergangs- und Validierungsregeln in technische Spezifikationen umgesetzt. Zusammen definieren sie die Geschäftslogik und die Prozesse für die Ausgabe, Aktualisierung, Verwaltung und Veröffentlichung von LEI-Daten im Common Data File (CDF) Format.
GLEIF operationalisiert diese Richtlinien, indem es sie in detaillierte technische Spezifikationen umwandelt und sie durch Datenqualitätsprüfungen implementiert, um sicherzustellen, dass die regulatorischen Absichten in den im System veröffentlichten LEI-Daten konsistent wiedergegeben werden.
Schaffung von Konsistenz durch Festlegung von Regeln für die Datenqualität
Im Mittelpunkt dieser Implementierung steht der GLEIF-Prozess zur Festlegung von Datenqualitätsregeln, ein strukturierter und systematischer Ansatz, der definiert, wie jede Datenqualitätsprüfung spezifiziert, interpretiert und im gesamten globalen LEI-System angewendet wird.
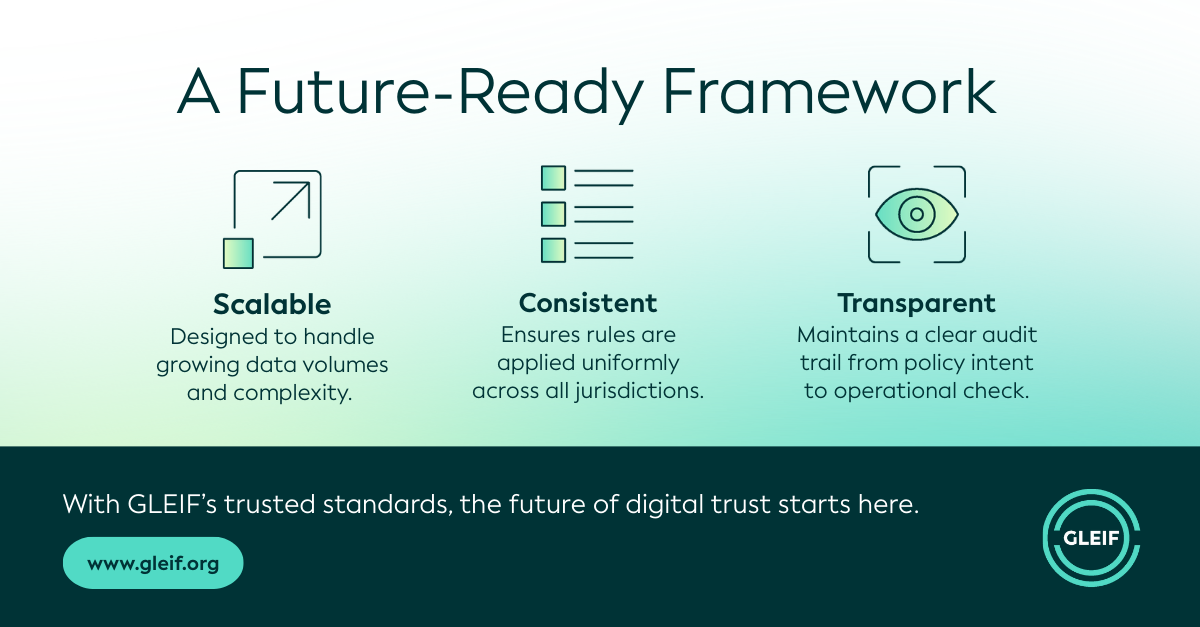
Durch die klare Formalisierung der Logik hinter jeder Prüfung gewährleistet der Prozess konsistente, reproduzierbare Auswertungen. Dies ermöglicht transparente, skalierbare Bewertungen der Datenqualität über Millionen von LEI-Datensätzen hinweg und trägt dazu bei, dass dieselben Regeln in allen Rechtsordnungen, Emittenten und Aktualisierungszyklen einheitlich angewendet werden.
Doch mit der Weiterentwicklung und dem Wachstum des globalen LEI-Systems steigt auch die Zahl der Regeln und der entsprechenden Prüfungen. Inzwischen gibt es mehr als 200 Prüfungen der Datenqualität, und dieser zunehmende Umfang führt zu zusätzlicher Komplexität und neuen Herausforderungen.
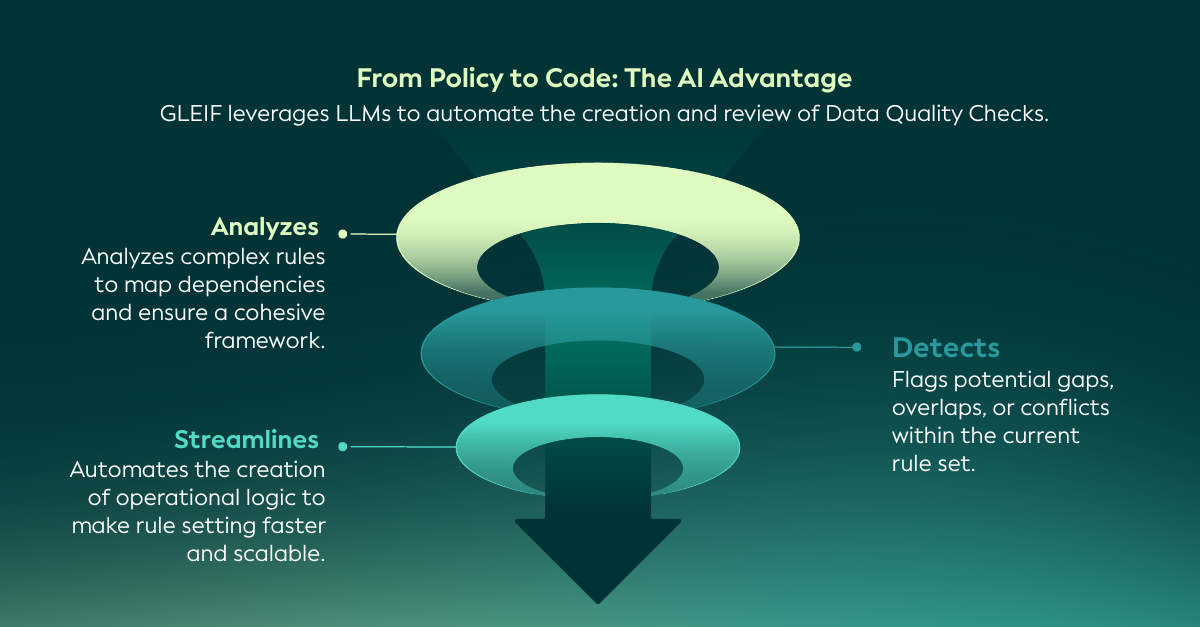
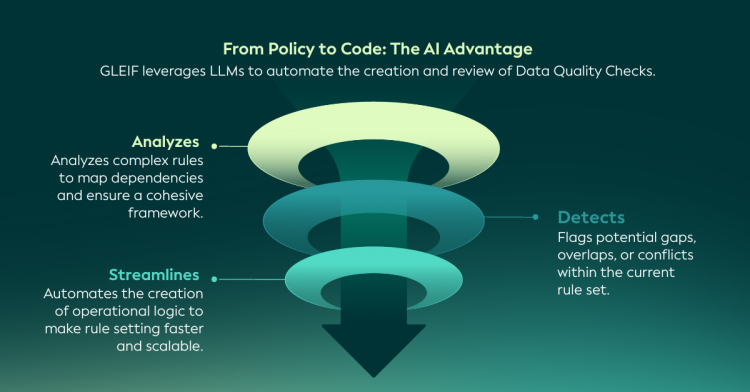
KI hilft dabei, diese neuen Überlegungen anzugehen. Durch die Unterstützung der Analyse komplexer, voneinander abhängiger Regeln lassen sich Überschneidungen oder Lücken zwischen den Prüfungen erkennen und die Erstellung und Pflege der Logik für die Datenqualität rationalisieren. Dadurch wird das gesamte Framework für die Datenqualität effizienter, anpassungsfähiger und skalierbarer - und bleibt gleichzeitig auf etablierten Governance-Prozessen aufgebaut.
Um zu veranschaulichen, wie dies in der Praxis funktioniert, bietet der folgende Abschnitt einen technischen Einblick in die Art und Weise, wie Large Language Models (LLMs) die strukturierte Umwandlung von Richtlinientext in maschinenlesbare Regeln und operative Datenqualitätsprüfungen unterstützen.
Tiefes Eintauchen: Übersetzen von Policy-Text in maschinenlesbare Regeln
GLEIF setzt LLMs ein, um die Identifizierung neuer Regeln zu unterstützen und potenzielle Widersprüche zu bestehenden Datenqualitätsprüfungen aufzudecken. Dies ermöglicht einen durchgängigen Überprüfungsprozess - von regulatorischen und politischen Dokumenten bis hin zu ihrer Implementierung.
Dieser Ansatz folgt einem klaren und strukturierten Arbeitsablauf, der sicherstellt, dass die politischen Absichten in den operativen Prüfungen im gesamten globalen LEI-System konsistent wiedergegeben werden. Der Arbeitsablauf lässt sich in den folgenden Phasen zusammenfassen:
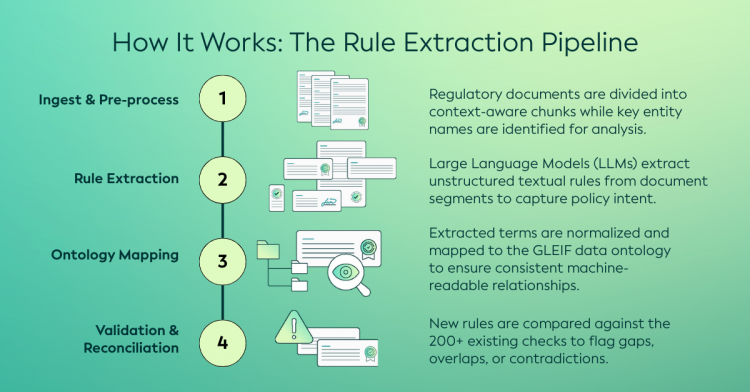
Vorverarbeitung: Der Prozess beginnt mit einer systematischen Analyse von Richtlinien- und Standarddokumenten, um relevante Regeln und Anforderungen zu identifizieren. KI hilft dabei, die in diesen Texten enthaltenen Schlüsselkonzepte und -bedingungen herauszuarbeiten, um sicherzustellen, dass wichtige regulatorische Erwartungen genau und umfassend erfasst werden. In dieser ersten Phase wird das Quelldokument eingelesen, um die relevanten Regeln zuverlässig zu extrahieren. Dies beinhaltet:
aufteilung des Dokuments in kontextabhängige Abschnitte
identifizierung von Entitätsnamen und Begriffen
das Filtern kontextbezogener Teile durch die Suche nach Schlüssel-Entitätsnamen
extraktion der unstrukturierten textuellen Regeln.
Beispiel: Eine internationale Zweigstelle ist eine Niederlassung einer juristischen Person ohne eigene Rechtspersönlichkeit, die sich in einer anderen Rechtsordnung befindet als ihr Hauptsitz.
Entitätsauflösung mit Ontologie-Mapping: Die in den formalen Dokumenten beschriebenen Anforderungen werden dann mit dem Sprachmodell der GLEIF-Regeln abgeglichen, um ein gemeinsames Verständnis darüber zu schaffen, wie Entitäten, Attribute und Beziehungen zu interpretieren sind. Dieser Schritt ist wichtig für die Konsistenz, um sicherzustellen, dass dieselben Konzepte einheitlich angewendet werden, auch wenn sie in den verschiedenen Quelldokumenten unterschiedlich beschrieben werden. Zu diesem Zweck werden die extrahierten Begriffe normalisiert und auf die GLEIF Rule Setting Ontologie abgebildet.
Beispiel:
"Eine internationale Niederlassung ist eine Niederlassung einer juristischen Person ohne eigene Rechtspersönlichkeit" wird abgebildet auf:
- *lei:EntityCategory IN ['BRANCH']
- *rr:RelationshipType IN ['_ISINTERNATIONALBRANCH_OF_']
"mit Sitz in einer anderen Rechtsordnung als der des Hauptsitzes" wird zugeordnet zu:
- *lei:LegalAddress/lei:Country NOT $EQUALS _$ENDNODERECORD_lei:LegalJurisdiction $COUNTRY_PART
Check-Erstellung und Validierung: Schließlich werden die abgeleiteten Regeln mit den bestehenden Prüfungen der Datenqualität abgeglichen, wobei die KI dabei hilft, festzustellen, wo bereits Prüfungen vorhanden sind, wo sie sich überschneiden und wo Widersprüche oder Lücken auftreten können. Dieser Ansatz hilft, die Komplexität von mehr als 200 Prüfungen zu bewältigen, wobei die Implementierung typischerweise Spezifikation, Entwicklung, Überprüfung, Test und Freigabe umfasst. Dies unterstützt eine kontrollierte, transparente Weiterentwicklung des Regelsatzes und stärkt die Gesamtkohärenz, Skalierbarkeit und Zuverlässigkeit des Rahmenwerks für Datenqualität.
Wie KI die Datenqualitätsprüfungen für eine transparentere globale Wirtschaft stärkt
Durch die Kombination von KI-gesteuerter Automatisierung mit menschlichem Fachwissen stärkt GLEIF sowohl die Effizienz als auch die Zuverlässigkeit seines Rahmenwerks für Datenqualität. Ein ontologiebasierter Ansatz sorgt für Konsistenz und Genauigkeit, während die zugrunde liegenden Prozesse so konzipiert sind, dass sie mit dem wachsenden Datenvolumen und der zunehmenden Komplexität Schritt halten können. Gleichzeitig unterstützt die künstliche Intelligenz die kontinuierliche Verbesserung, indem sie Mehrdeutigkeiten in der Regelsprache hervorhebt und Möglichkeiten zur Verfeinerung der Methoden aufzeigt. Zusammen verstärken diese Fähigkeiten einen belastbaren, transparenten und zukunftsfähigen Ansatz für die Datenqualität im gesamten Global LEI System.
Falls Sie einen Blogbeitrag kommentieren möchten, besuchen Sie zum Posten Ihres Kommentars bitte die Blog-Funktion auf der englischsprachigen GLEIF-Website. Bitte identifizieren Sie sich mit Ihrem Vor- und Nachnamen. Ihr Name erscheint neben Ihrem Kommentar. Die E-Mail-Adresse wird nicht veröffentlicht. Bitte beachten Sie, dass Sie sich durch Zugriff auf oder Beiträge zum Diskussionsforum verpflichten, die Bedingungen der GLEIF-Blogging-Richtlinie einzuhalten. Lesen Sie sich diese daher sorgfältig durch.
Zornitsa Manolova leitet das Team für Datenqualitätsmanagement und Datenwissenschaft bei der Global Legal Entity Identifier Foundation (GLEIF). Seit April 2018 ist sie für die Erweiterung und Verbesserung der etablierten Rahmenordnung zu Datenqualität und Daten-Governance durch Umsetzung innovativer Ansätze zur Datenanalyse zuständig. Zuvor leitete sie Projekte zur Analyse forensischer Daten im Rahmen internationaler Finanzuntersuchungen bei PwC Forensics. Sie verfügt über ein deutsches Diplom in Informatik mit Schwerpunkt auf Maschinellem Lernen von der Philipps-Universität Marburg.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
