Übersetzungen dieser Website in andere Sprachen als Englisch werden von KI unterstützt. Wir garantieren keine Genauigkeit und haften nicht für Fehler oder Schäden, die sich aus der Nutzung der übersetzten Inhalte ergeben. Im Falle von Unstimmigkeiten oder Unklarheiten gilt die englische Version als maßgebend.
Newsroom & Medien
GLEIF-Blogbeiträge
Übersetzungen dieser Website in andere Sprachen als Englisch werden von KI unterstützt. Wir garantieren keine Genauigkeit und haften nicht für Fehler oder Schäden, die sich aus der Nutzung der übersetzten Inhalte ergeben. Im Falle von Unstimmigkeiten oder Unklarheiten gilt die englische Version als maßgebend.
Daten in Chancen verwandeln: „Metric in Motion“ – Wie KI die Eigentumstransparenz stärken kann
Unternehmen stützen sich zunehmend auf Beziehungsdaten für Risikomanagement, Due Diligence, Compliance und Transparenz. In diesem Blogbeitrag untersucht Zornitsa Manolova, Leiterin des Bereichs Datenqualität und Data Science bei der GLEIF, wie KI neue Möglichkeiten bietet, die Qualität, Vollständigkeit und Zugänglichkeit vertrauenswürdiger Eigentumsinformationen in großem Maßstab zu verbessern.
Autor: Zornitsa Manolova
Datum: 2026-06-08
Ansichten:
In einer zunehmend vernetzten Weltwirtschaft ist die Fähigkeit von Organisationen, Daten zu vertrauen und effektiv zu nutzen, die Grundlage für Innovation, Wachstum und Wettbewerbsfähigkeit.
Ein hochwertiges Datenökosystem ist ein Motor für Wandel und Innovation, der es Organisationen ermöglicht, neue Chancen zu erkennen und zu nutzen, während eine geringe Datenqualität zu Ineffizienzen und der Gefährdung durch regulatorische und Reputationsrisiken führen kann.
Um das Bewusstsein der Branche für die Initiativen zur Datenqualität der GLEIF und deren Anwendung in verschiedenen Sektoren zu stärken, beleuchtet diese neue Blogserie wichtige Kennzahlen aus den Berichten.
Der Schwerpunkt dieses Monats: Wie KI die Transparenz von Eigentumsverhältnissen stärken kann.
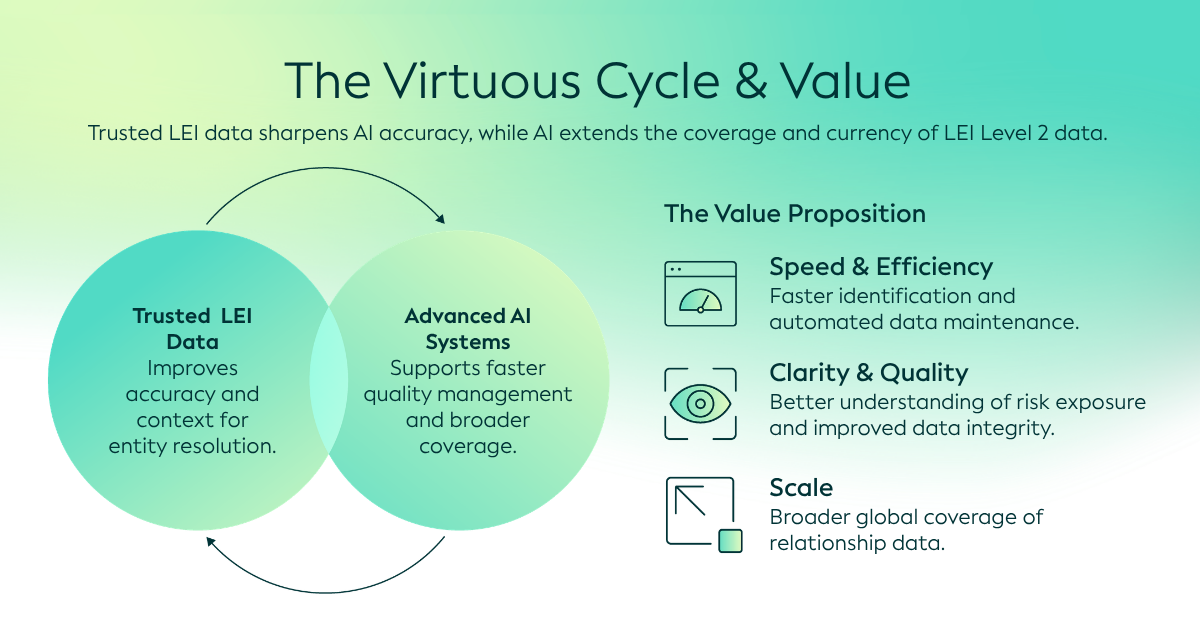
Da globale Unternehmensstrukturen immer komplexer werden, wird der Zugang zu vertrauenswürdigen Daten über Eigentumsverhältnisse und Beziehungen für Transparenz, Rechenschaftspflicht und Risikoeinblicke immer wichtiger. Diese Daten, die Beziehungen zwischen Mutter- und Tochtergesellschaften umfassen, helfen Organisationen dabei, Risiken zu bewerten, die Compliance zu unterstützen und fundiertere Entscheidungen zu treffen, indem sie aufzeigen, wie Rechtsträger miteinander verbunden sind.
Im Globalen LEI-System liefern Level-2-Daten diesen entscheidenden Kontext, indem sie Mutter- und Tochtergesellschaftsstrukturen, Verbindungen zwischen Niederlassungen und Hauptsitzen sowie Fondsbeziehungen identifizieren. Oft als Antwort auf die Frage „Wer gehört wem?“ beschrieben, helfen Level-2-Daten dabei, die Strukturen hinter Rechtsträgern aufzudecken und das Vertrauen in Finanz- und Geschäftsökosystemen zu stärken.
Den Wert von Level-2-Daten im Globalen LEI-System verstehen
Eine kürzlich vom Regulatory Oversight Committee (ROC) und der GLEIF durchgeführte Umfrage unterstreicht den Wert von Level-2-Daten. Etwa 70 % der Befragten gaben an, Level-2-Daten zu nutzen, während fast 85 % diese als qualitativ hochwertige Daten einstuften. Die Befragten bestätigten zudem, dass Level-2-Daten bereits in die Entscheidungsfindung ihrer Organisationen integriert sind, und gaben an, Level-2-Daten zur Unterstützung verschiedener operativer und strategischer Prozesse zu nutzen, wobei viele insbesondere konsolidierte Muttergesellschaftsbeziehungen schätzen.
Diese Ergebnisse verdeutlichen einen wichtigen Trend. Da die Nachfrage nach zuverlässigen Informationen zur Eigentümerschaft steigt, ist die Pflege hochwertiger Beziehungsdaten in großem Maßstab von entscheidender Bedeutung.
KI eröffnet neue Möglichkeiten für die Extraktion von Beziehungsdaten
Da künstliche Intelligenz (KI) die Art und Weise verändert, wie Unternehmen Daten verwalten und analysieren, ergeben sich neue Möglichkeiten, um diesem Bedarf gerecht zu werden und die Qualität, Vollständigkeit und Zuverlässigkeit von Beziehungsdaten weiter zu verbessern.
So sind wertvolle Informationen zu Unternehmensbeziehungen zwar bereits weit verbreitet, oft jedoch schwer zugänglich, da sie in Jahresberichten und anderen Unternehmensveröffentlichungen verborgen sind. Angaben zu Mutter- und Tochtergesellschaften können in Fußnoten, Tabellen, Anhangangaben oder beschreibenden Abschnitten enthalten sein. Diese Angaben sind oft fragmentiert, uneinheitlich formatiert und lassen sich manuell nur schwer in großem Umfang überprüfen, was ihre Integration in strukturierte Datensätze erschwert.
Die KI-gestützte Extraktion bietet eine praktische Möglichkeit, diese verborgenen Informationen zugänglich zu machen. Durch die Identifizierung, Interpretation und Strukturierung von Eigentumsangaben aus Jahresberichten und anderen komplexen PDF-Dokumenten kann KI dabei helfen, unstrukturierte Informationen in strukturierte Beziehungsdaten umzuwandeln. Sie kann zudem Informationen dokumentenübergreifend vergleichen. Dies kann die Erfassung und Validierung von Level-2-Daten verbessern, eine bessere Risikoanalyse und Entscheidungsfindung unterstützen und die Gesamtqualität sowie die Transparenz des Globalen LEI-Systems steigern.
Tatsächlich nutzt die GLEIF bereits KI-basierte Extraktion, um die Beziehungsdaten aus Geschäftsberichten abzurufen und in ein strukturiertes Format zu konvertieren. Dies ermöglicht es der GLEIF, bestehende Beziehungsinformationen im Global LEI Index zu überprüfen und zu bestätigen oder bei Bedarf Aktualisierungen außerhalb des jährlichen Erneuerungsprozesses auszulösen. Dadurch können Beziehungsdaten im Laufe der Zeit aktueller und vertrauenswürdiger gehalten werden.
Fortschritte bei der „Transparency Fabric“ – einer gemeinsamen Initiative von GLEIF, Open Ownership und OpenSanctions – im Jahr 2025 wurde zudem der Einsatz von Large Language Models (LLMs) eingeführt, um Informationen aus unstrukturierten Dokumenten zu extrahieren und zu analysieren, um komplexe Eigentumsverhältnisse besser abzubilden und die Verknüpfung von LEIs mit Daten zu wirtschaftlichen Eigentümern und Sanktionen zu unterstützen.
So funktioniert es
Der automatisierte Prozess identifiziert alle Tochtergesellschaften von Muttergesellschaften in einem Jahresbericht im PDF-Format mithilfe eines mehrstufigen LLM-Prozesses:
Zunächst überprüft die KI den Bericht und identifiziert mögliche Tochtergesellschaften auf der Grundlage der bereitgestellten Definitionen und Beispiele. Anschließend überprüft sie ihre eigenen Ergebnisse, um potenzielle Lücken, fehlende Tochtergesellschaften oder möglicherweise falsch eingeordnete Einträge zu identifizieren.
Nach dieser Überprüfung werden die Ergebnisse zu einer endgültigen Liste im erforderlichen Format verfeinert. Dazu gehören das Entfernen von Fehlalarmen, das Hinzufügen übersehener Tochtergesellschaften, die Überprüfung der entsprechenden Seitenverweise sowie die Standardisierung von Details wie Gerichtsbarkeits- oder Länderinformationen.
Schließlich kann die KI-generierte Liste mit einer manuell extrahierten Liste verglichen werden, um Genauigkeit, Vollständigkeit und Gesamtqualität zu bewerten.
Dies zeigt, wie KI dazu beitragen kann, die Extraktion von Tochtergesellschaftsdaten aus komplexen PDF-Dokumenten zu beschleunigen. Gleichzeitig bleibt die Einbeziehung menschlicher Kontrolle wichtig, um die Ergebnisse zu validieren, die Qualität zu verbessern und sicherzustellen, dass die endgültigen Beziehungsdaten zuverlässig sind.
Verwendung vertrauenswürdiger LEI-Daten zur Verbesserung der KI selbst
Während KI dabei helfen kann, Level-2-Beziehungsdaten zu finden und zu überprüfen, können vertrauenswürdige LEI-Daten wiederum den Einsatz von KI-Methoden für diese Aufgabe verbessern.
Die GLEIF hat vorhandene LEI-Daten und Jahresberichte genutzt, um Prompts mithilfe des GEPA-Ansatzes (Genetic Pareto Reflective Prompt Evolution) zu optimieren. Anstatt zu raten, welcher Prompt am besten funktionieren könnte, nutzt GEPA gekennzeichnete Daten und menschliches Feedback, um leistungsfähigere Prompt-Varianten zu entwickeln, diese anhand bekannter Beispiele zu testen und die besten Kompromisslösungen beizubehalten.
Dieser Ansatz verlagert die KI-Entwicklung vom Experimentieren hin zu messbaren Verbesserungen. So verbesserte beispielsweise eine durch GEPA optimierte Eingabeaufforderung die messbare Genauigkeit der abgerufenen Beziehungsinformationen. Noch interessanter ist, dass ein kleineres und kostengünstigeres Modell nach der Optimierung eine bessere Leistung erbrachte als ein größeres und teureres Modell. Dies zeigt, dass hochwertige Daten und strukturierte Optimierung oft wichtiger sind als die Verwendung eines größeren Modells. Einfach ausgedrückt: Bessere Eingaben führen zu besseren Ergebnissen.
Kombination von KI-Innovation mit vertrauenswürdigen Datengrundlagen
Das wertvollste Ergebnis der KI-gesteuerten Extraktion von Beziehungsdaten ist die Fähigkeit, fragmentierte Offenlegungen in zuverlässige, strukturierte und verwertbare Beziehungsinformationen umzuwandeln – was es Organisationen ermöglicht, fundiertere Entscheidungen in der globalen Wirtschaft zu treffen.
Dennoch bleiben vertrauenswürdige Rahmenbedingungen, Governance und standardisierte Identifikatoren unerlässlich, um sicherzustellen, dass diese Erkenntnisse zuverlässig und nutzbar sind. Durch die Kombination von KI-Innovation mit den vertrauenswürdigen Grundlagen des Globalen LEI-Systems bietet sich die Möglichkeit, die Qualität, Abdeckung und Nutzbarkeit von Eigentums- und Beziehungsdaten in großem Maßstab zu stärken.
Falls Sie einen Blogbeitrag kommentieren möchten, besuchen Sie zum Posten Ihres Kommentars bitte die Blog-Funktion auf der englischsprachigen GLEIF-Website. Bitte identifizieren Sie sich mit Ihrem Vor- und Nachnamen. Ihr Name erscheint neben Ihrem Kommentar. Die E-Mail-Adresse wird nicht veröffentlicht. Bitte beachten Sie, dass Sie sich durch Zugriff auf oder Beiträge zum Diskussionsforum verpflichten, die Bedingungen der GLEIF-Blogging-Richtlinie einzuhalten. Lesen Sie sich diese daher sorgfältig durch.
Zornitsa Manolova leitet das Team für Datenqualitätsmanagement und Datenwissenschaft bei der Global Legal Entity Identifier Foundation (GLEIF). Seit April 2018 ist sie für die Erweiterung und Verbesserung der etablierten Rahmenordnung zu Datenqualität und Daten-Governance durch Umsetzung innovativer Ansätze zur Datenanalyse zuständig. Zuvor leitete sie Projekte zur Analyse forensischer Daten im Rahmen internationaler Finanzuntersuchungen bei PwC Forensics. Sie verfügt über ein deutsches Diplom in Informatik mit Schwerpunkt auf Maschinellem Lernen von der Philipps-Universität Marburg.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
