
Dane LEI
Zarządzanie jakością danych GLEIF
Zapewnienie jakości danych wymaga proaktywnych działań
Zarządzanie proaktywne
W celu wsparcia podmiotów nadających LEI GLEIF zapewnia wdrożenie odpowiednich procesów wraz z interfejsem technicznym, aby umożliwić tym podmiotom proaktywną ocenę jakości danych LEI i powiązanych danych referencyjnych. Zakres tych działań obejmuje specjalną kontrolę pod kątem występowania duplikatów wpisów. Rejestry LEI są sprawdzane pojedynczo przy użyciu zautomatyzowanych interfejsów webowych API: wstępnej kontroli zarządzania danymi i kontroli pod kątem występowania duplikatów.
Wstępna kontrola zarządzania danymi

Podmioty nadające LEI są zobowiązane do przesyłania wszystkich nowo wydanych i zaktualizowanych rekordów LEI do modułu kontroli wstępnej GLEIF przed załadowaniem ich do globalnego repozytorium. W ramach modułu kontroli wstępnej GLEIF stosuje się kontrole jakości danych, które w takim samym zakresie są już codziennie przeprowadzane na opublikowanych rekordach LEI. Na podstawie wyników kontroli wstępnej podmioty nadające LEI mogą rozwiązać potencjalne problemy z jakością danych, zanim wszelkie niespójności danych trafią do publicznej puli danych. Oprócz wyniku kontroli wnioskodawca otrzymuje również wyjaśnienie, które ułatwia ukierunkowanie działań naprawczych i szybkie wyeliminowanie zgłoszonego problemu.
Obowiązkowe zastosowanie modułu przez podmioty nadające LEI wspiera proces ciągłego doskonalenia, podnosząc poprzeczkę w zakresie zapewnienia jakości i zwiększając poziom dojrzałości danych w Globalnym Systemie LEI.
Kontrola duplikatów
Aby zapobiec duplikacji rekordów danych, nowe kody LEI i odpowiadające im dane referencyjne są porównywane z wszystkimi innymi rekordami w Globalnym Repozytorium LEI, jak również z rekordami LEI, które zostały przedłożone do modułu kontroli duplikatów przez inne podmioty nadające LEI, ale nie zostały jeszcze nadane. Dlatego też, nawet jeżeli ten sam podmiot prawny zwróci się do dwóch różnych podmiotów nadających LEI, podmioty te zidentyfikują potencjalne duplikaty i będą w stanie koordynować działania ze swoimi klientami oraz między sobą. Finalnie procedura ta zapobiega wprowadzaniu duplikatów do systemu.
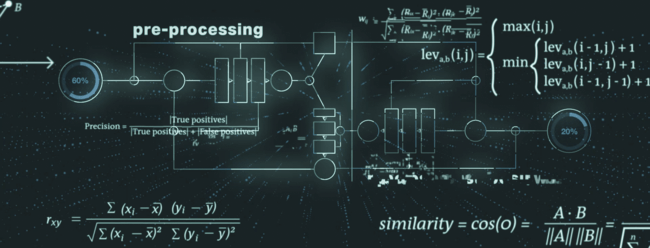
W procesie identyfikacji duplikatów uwzględnia się szereg elementów w rekordzie LEI. Proces ten można podzielić na następujące etapy: przetwarzanie wstępne, algorytm podstawowy i przetwarzanie końcowe.
Podczas przetwarzania wstępnego dane są przygotowywane do kolejnych etapów, na przykład identyfikuje się i przygotowuje do przetwarzania tzw. słabe tokeny. Typowym przykładem słabego tokena jest forma prawna podmiotu prawnego, która może być częścią jego nazwy. Formy prawne mogą być następnie normalizowane i harmonizowane, aby zapewnić najlepsze wyniki na kolejnych etapach procesu.
Z wykorzystaniem najnowocześniejszych algorytmów dopasowywania ciągów rozmytych (np. odległość Levenshteina, podobieństwo cosinusowe, odległość Monge-Elkana) główny mechanizm modułu kontroli duplikatów obejmuje sprawdzenie unikatowości i wyłączności rekordów.
Na etapie przetwarzania końcowego moduł kontroli duplikatów – w oparciu o dodatkowe kontrole i specjalną analizę wtórnych elementów danych (np. jurysdykcja, kategoria podmiotu) – zmniejsza liczbę wyników fałszywie pozytywnych.
Odpowiednie pliki do pobrania
Pobierz w formacie PDF: Słownik kontroli duplikatów wer. 1.2 (Check for Duplicates Dictionary v1.2)