Tłumaczenia na języki inne niż angielski na tej stronie internetowej są wspomagane przez sztuczną inteligencję. Nie gwarantujemy dokładności i nie ponosimy odpowiedzialności za błędy lub szkody wynikające z korzystania z przetłumaczonych treści. W przypadku jakichkolwiek niespójności lub niejasności, wersja angielska ma pierwszeństwo.
Prasa i media
Blog GLEIF
Tłumaczenia na języki inne niż angielski na tej stronie internetowej są wspomagane przez sztuczną inteligencję. Nie gwarantujemy dokładności i nie ponosimy odpowiedzialności za błędy lub szkody wynikające z korzystania z przetłumaczonych treści. W przypadku jakichkolwiek niespójności lub niejasności, wersja angielska ma pierwszeństwo.
Strategiczne trendy w jakości danych: Metric in Motion - podejście do jakości danych oparte na sztucznej inteligencji
Jakość danych to coś więcej niż punkt odniesienia - to strategiczna konieczność dla globalnego zaufania, Zgodności i interoperacyjności. W tym blogu Zornitsa Manolova, Head of Jakość danych Management and Data Science w GLEIF, bada, w jaki sposób sztuczna inteligencja pomaga wzmocnić kontrole jakości danych w celu zbudowania bardziej przejrzystej globalnej gospodarki.
Autor: Zornitsa Manolova
Data: 2026-02-06
Odsłon:
W coraz bardziej wzajemnie powiązanej globalnej gospodarce zdolność organizacji do zaufania i efektywnego wykorzystywania danych jest podstawą innowacji, wzrostu i konkurencyjności.
Wysokiej jakości ekosystem danych jest motorem zmian i innowacji, który umożliwia organizacjom identyfikowanie i wykorzystywanie nowych możliwości, podczas gdy niska jakość danych może prowadzić do nieefektywności i narażenia na ryzyko regulacyjne i reputacyjne.
GLEIF jest zaangażowana w optymalizację jakości, wiarygodności i użyteczności danych LEI. Od 2017 r. publikuje comiesięczne raporty w celu przejrzystego wykazania ogólnej jakości danych osiągniętej w Globalnym Systemie LEI.
Aby pomóc szerszej branży w zrozumieniu i uświadomieniu sobie inicjatyw GLEIF w zakresie jakości danych, ta nowa seria blogów analizuje kluczowe wskaźniki zawarte w raportach.
W tym miesiącu na blogu podkreślono, w jaki sposób sztuczna inteligencja pomaga usprawnić kontrole jakości danych.
Zapewnienie wiarygodnych danych LEI w skali globalnej wymaga spójnej interpretacji wymogów regulacyjnych i politycznych. W miarę jak wymogi te ewoluują i stają się coraz bardziej złożone, sztuczna inteligencja wzmacnia możliwości GLEIF w zakresie skalowalnego zapewniania jakości przy jednoczesnym zagwarantowaniu, że przejrzystość i zarządzanie pozostaną w centrum uwagi.
Od wymogów polityki do kontroli jakości danych
Komitet Nadzoru Regulacyjnego (ROC) definiuje zasady biznesowe i polityki rządzące Globalnym Systemem LEI. Wymagania te są następnie opisywane i przekładane na specyfikacje techniczne za pomocą reguł przejścia między stanami i reguł walidacji. Razem definiują one logikę biznesową i procesy nadawania, aktualizacji, zarządzania i publikacji danych LEI w formacie Common Data File (CDF).
GLEIF operacjonalizuje te zasady, przekształcając je w szczegółowe specyfikacje techniczne i wdrażając je poprzez kontrole jakości danych, zapewniając spójne odzwierciedlenie intencji regulacyjnych w danych LEI publikowanych w całym systemie.
Budowanie spójności poprzez ustalanie zasad jakości danych
Centralnym elementem tego wdrożenia jest proces ustanawiania zasad jakości danych GLEIF, ustrukturyzowane i systematyczne podejście, które definiuje sposób, w jaki każda kontrola jakości danych jest określana, interpretowana i stosowana w Globalnym Systemie LEI.
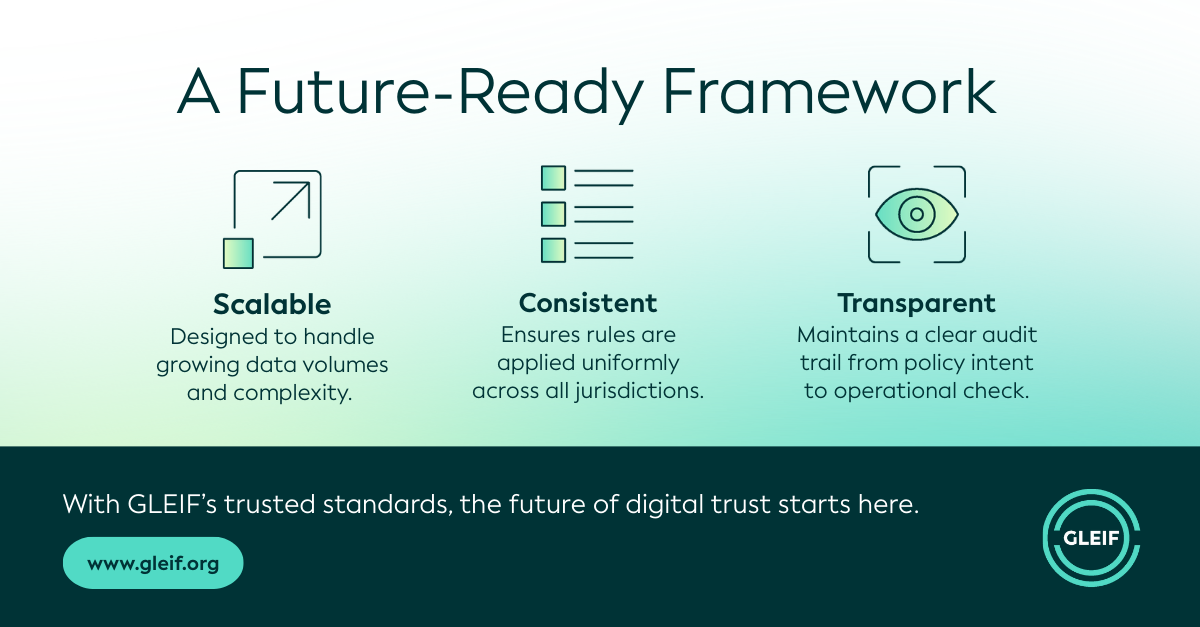
Poprzez jasne sformalizowanie logiki stojącej za każdą kontrolą, proces ten zapewnia spójne, powtarzalne oceny. Umożliwia to przejrzyste, skalowalne oceny Jakości danych w milionach rekordów LEI i pomaga zapewnić spójne stosowanie tych samych zasad w różnych jurysdykcjach, podmiotach nadających LEI i cyklach aktualizacji.
Jednak wraz z ewolucją i rozwojem Globalnego Systemu LEI rośnie również liczba zasad i odpowiadających im kontroli. Obecnie istnieje ponad 200 kontroli jakości danych, a rosnąca skala wprowadza dodatkową złożoność i nowe wyzwania.
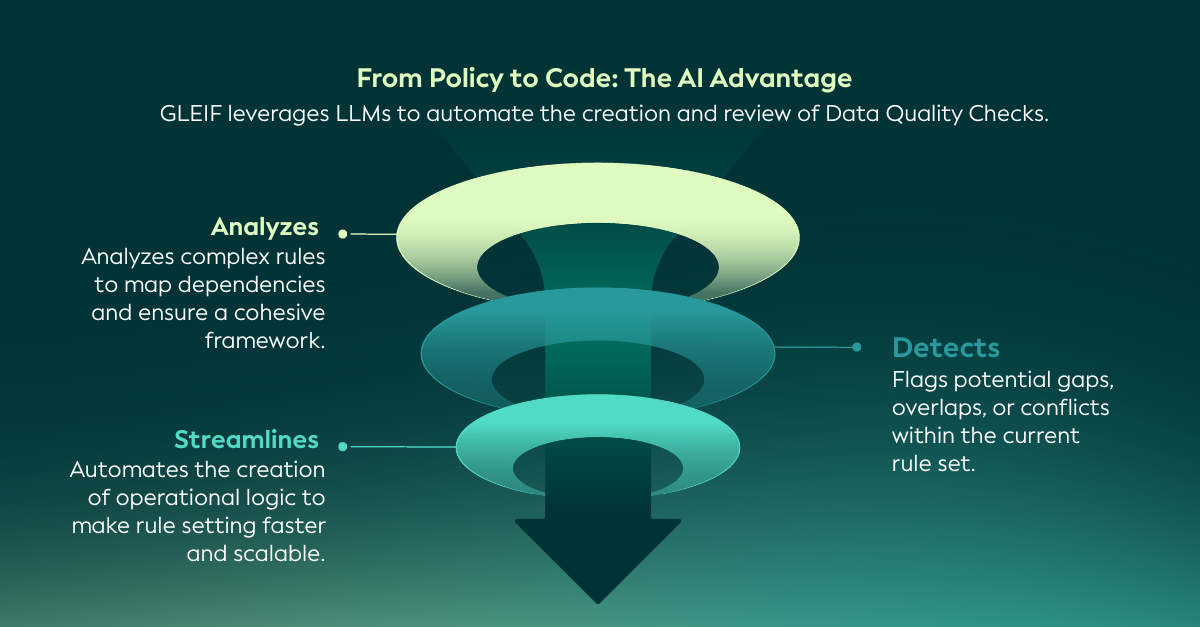
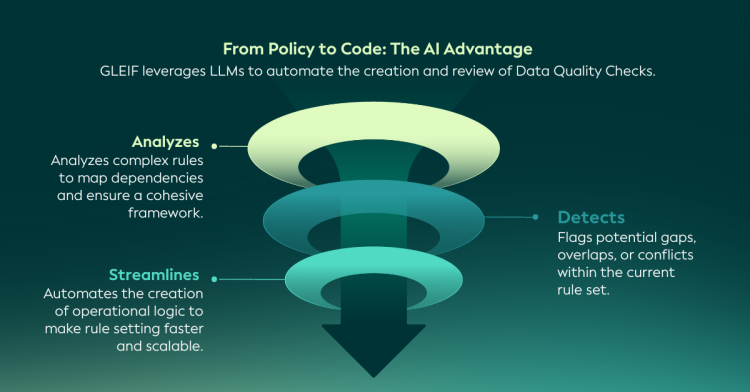
Sztuczna inteligencja pomaga sprostać tym nowym wyzwaniom. Wspieranie analizy złożonych, współzależnych reguł pomaga zidentyfikować nakładanie się lub luki w kontrolach oraz usprawnia tworzenie i utrzymywanie logiki jakości danych. W rezultacie ogólna struktura jakości danych staje się bardziej wydajna, elastyczna i skalowalna - pozostając jednocześnie oparta na ustalonych procesach zarządzania.
Aby zilustrować, jak to działa w praktyce, poniższa sekcja przedstawia techniczne zagłębienie się w sposób, w jaki duże modele językowe (LLM) wspierają ustrukturyzowaną konwersję tekstu polityki na reguły nadające się do odczytu maszynowego i operacyjne kontrole jakości danych.
Szczegółowa analiza: Przekształcanie tekstu polityki w reguły nadające się do odczytu maszynowego
GLEIF wykorzystuje modele LLM, aby wspierać identyfikację nowych reguł i pomagać w wykrywaniu potencjalnych sprzeczności z istniejącymi kontrolami jakości danych, umożliwiając kompleksowy proces przeglądu - od dokumentów regulacyjnych i politycznych po ich wdrożenie.
Podejście to opiera się na jasnym i ustrukturyzowanym przepływie pracy, który zapewnia, że intencje polityki są konsekwentnie odzwierciedlane w kontrolach operacyjnych w Globalnym Systemie LEI. Proces ten można podsumować w następujących etapach:
Przetwarzanie wstępne: Proces rozpoczyna się od systematycznej analizy dokumentów dotyczących polityki i standardów w celu zidentyfikowania odpowiednich zasad i wymogów. Sztuczna inteligencja pomaga wyodrębnić kluczowe pojęcia i warunki zawarte w tych tekstach, zapewniając dokładne i kompleksowe uchwycenie ważnych oczekiwań regulacyjnych. Na tym początkowym etapie dokument źródłowy jest pozyskiwany w celu niezawodnego wyodrębnienia odpowiednich reguł. Obejmuje to
podział dokumentu na fragmenty uwzględniające kontekst
identyfikację nazw jednostek i terminów
filtrowanie fragmentów z uwzględnieniem kontekstu poprzez wyszukiwanie według klucza-nazwy jednostki
Przykład: Międzynarodowy oddział jest nieposiadającym osobowości prawnej zakładem podmiotu prawnego zlokalizowanym w innej jurysdykcji niż jego siedziba główna.
Entity Resolution with Ontology Mapping: Wymagania opisane w dokumentach formalnych są następnie dostosowywane do modelu języka reguł GLEIF, tworząc wspólne zrozumienie tego, jak należy interpretować jednostki, atrybuty i relacje. Krok ten ma zasadnicze znaczenie dla spójności, zapewniając jednolite stosowanie tych samych pojęć, nawet jeśli są one opisane w różny sposób w dokumentach źródłowych. W tym celu wyodrębnione terminy są normalizowane i mapowane do ontologii GLEIF Rule Setting.
Przykład:
"An international branch is a non-incorporated establishment of a legal entity" is mapped to:
- *lei:EntityCategory IN ['BRANCH']
- *rr:RelationshipType IN ['_ISINTERNATIONALBRANCH_OF_']
"located in a different jurisdiction than its head office" jest mapowane do:
- *lei:LegalAddress/lei:Country NOT $EQUALS _$ENDNODERECORD_lei:LegalJurisdiction $COUNTRY_PART
Tworzenie i walidacja kontroli: Na koniec wyprowadzone reguły są uzgadniane z istniejącymi kontrolami jakości danych, przy czym sztuczna inteligencja pomaga zidentyfikować, gdzie kontrole już istnieją, gdzie się pokrywają i gdzie mogą pojawić się sprzeczności lub luki. Podejście to pomaga zarządzać złożonością ponad 200 kontroli, przy czym wdrożenie zazwyczaj obejmuje specyfikację, rozwój, przegląd, testowanie i wydanie. Wspiera to kontrolowaną, przejrzystą ewolucję zestawu reguł i wzmacnia ogólną spójność, skalowalność i niezawodność ram jakości danych.
Jak sztuczna inteligencja wzmacnia kontrole jakości danych dla bardziej przejrzystej globalnej gospodarki
Łącząc automatyzację opartą na sztucznej inteligencji z ludzką wiedzą, GLEIF wzmacnia zarówno wydajność, jak i niezawodność swoich ram jakości danych. Podejście oparte na ontologii zapewnia spójność i dokładność, podczas gdy podstawowe procesy są zaprojektowane tak, aby skalować się wraz ze wzrostem ilości i złożoności danych. Jednocześnie sztuczna inteligencja wspiera ciągłe doskonalenie, podkreślając niejednoznaczności w języku reguł i ujawniając możliwości udoskonalenia metodologii. Razem możliwości te wzmacniają odporne, przejrzyste i gotowe na przyszłość podejście do jakości danych w Globalnym Systemie LEI.
Osoby pragnące umieścić wpis w blogu prosimy o odwiedzenie strony: funkcje internetowego blogu GLEIF w języku angielskim. Imię i nazwisko autora komentarza pojawi się obok wpisu. Adresy e-mail nie będą publikowane. Uczestnictwo w forum dyskusyjnym i korzystanie z niego oznacza zgodę na przestrzeganie obowiązujących Zasad korzystania z blogu GLEIF, które należy uważnie przeczytać.
Zornitsa Manolova kieruje zespołem ds. zarządzania jakością danych i nauki o danych w Global Legal Entity Identifier Foundation (GLEIF). Od kwietnia 2018 roku odpowiada za doskonalenie i poprawę ustalonych ram jakości danych i zarządzania danymi poprzez wprowadzanie innowacyjnych metod analizy danych. Wcześniej Zornitsa zarządzała projektami analizy danych kryminalistycznych w ramach międzynarodowych dochodzeń finansowych w PwC Forensics. Uzyskała niemiecki dyplom z zakresu nauk komputerowych z ukierunkowaniem na uczenie maszynowe na Uniwersytecie w Marburgu.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
